# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rowsElements of Data Science
SDS 322E
Tidy data

- Each variable is a column
- Each observation is a row
- Each cell is a single value
Is this tidy? (1/8)
income and religion in the US produced by Pew Research Center in 2014
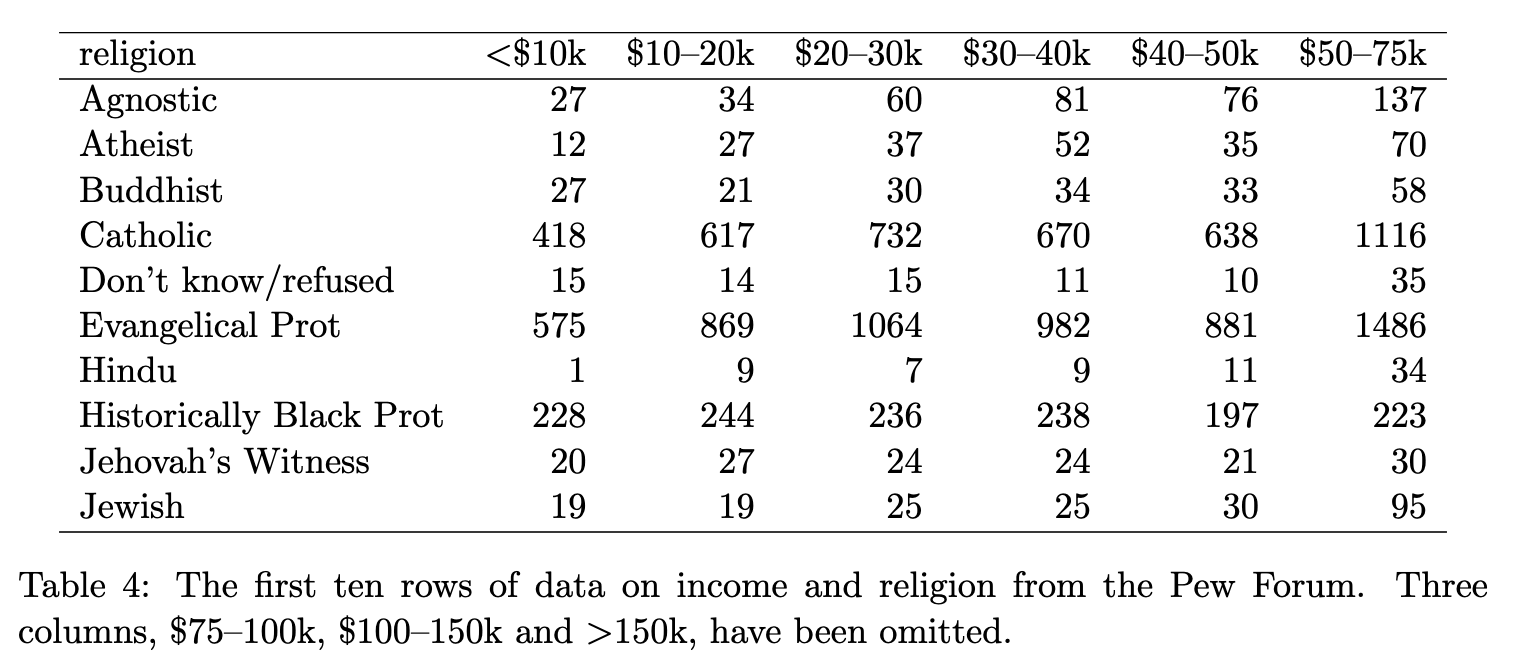
❌ No, because values (<$10k, $10-20k, $20-30k, …) are in variable names
Is this tidy? (2/8)
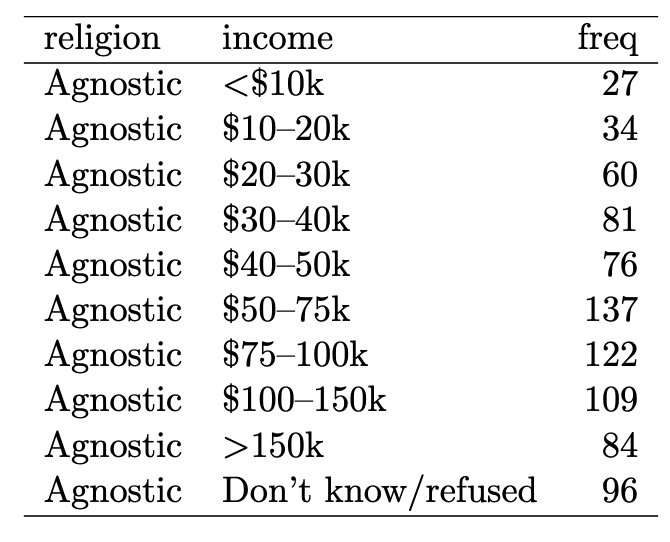
✅ Yes, because 1) The variables are: religion, income, and freq (count), 2) The observation is a demographic unit corresponding to a combination of religion and income
Is this tidy? (3/8)
The Billboard dataset: the date a song first entered the Billboard Top 100
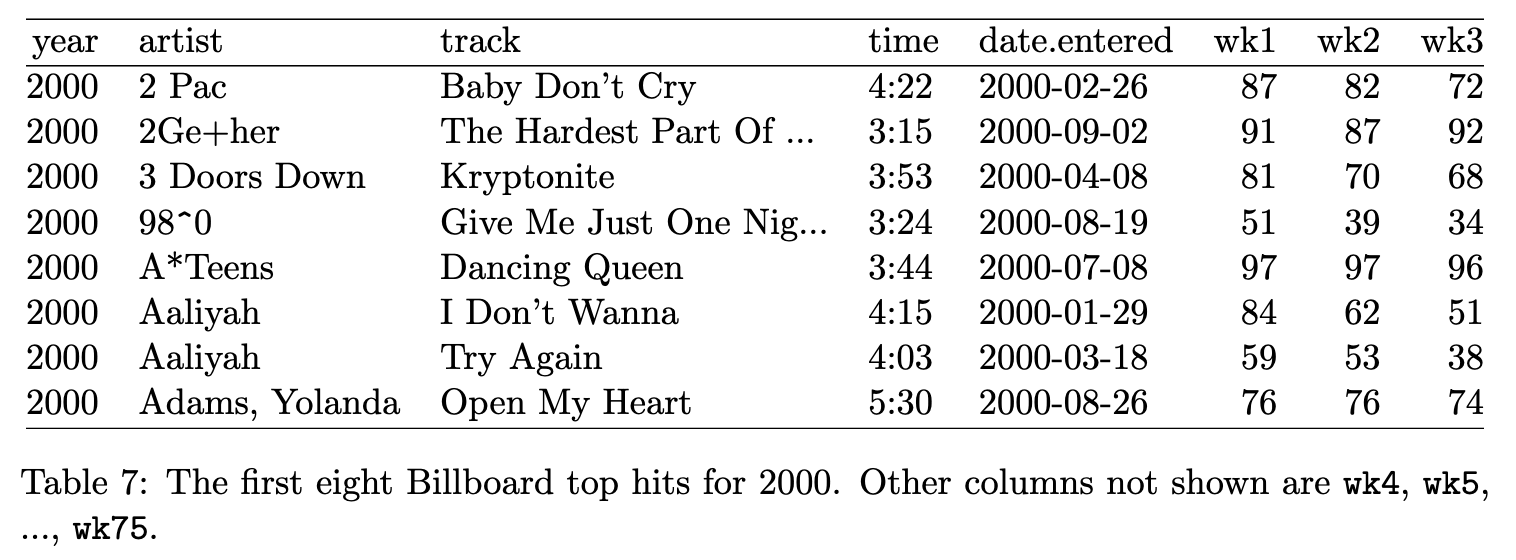
❌: No, because wk1, wk2, … are values, not variables - they should be recorded in cells rather than in column names
Is this tidy? (4/8)
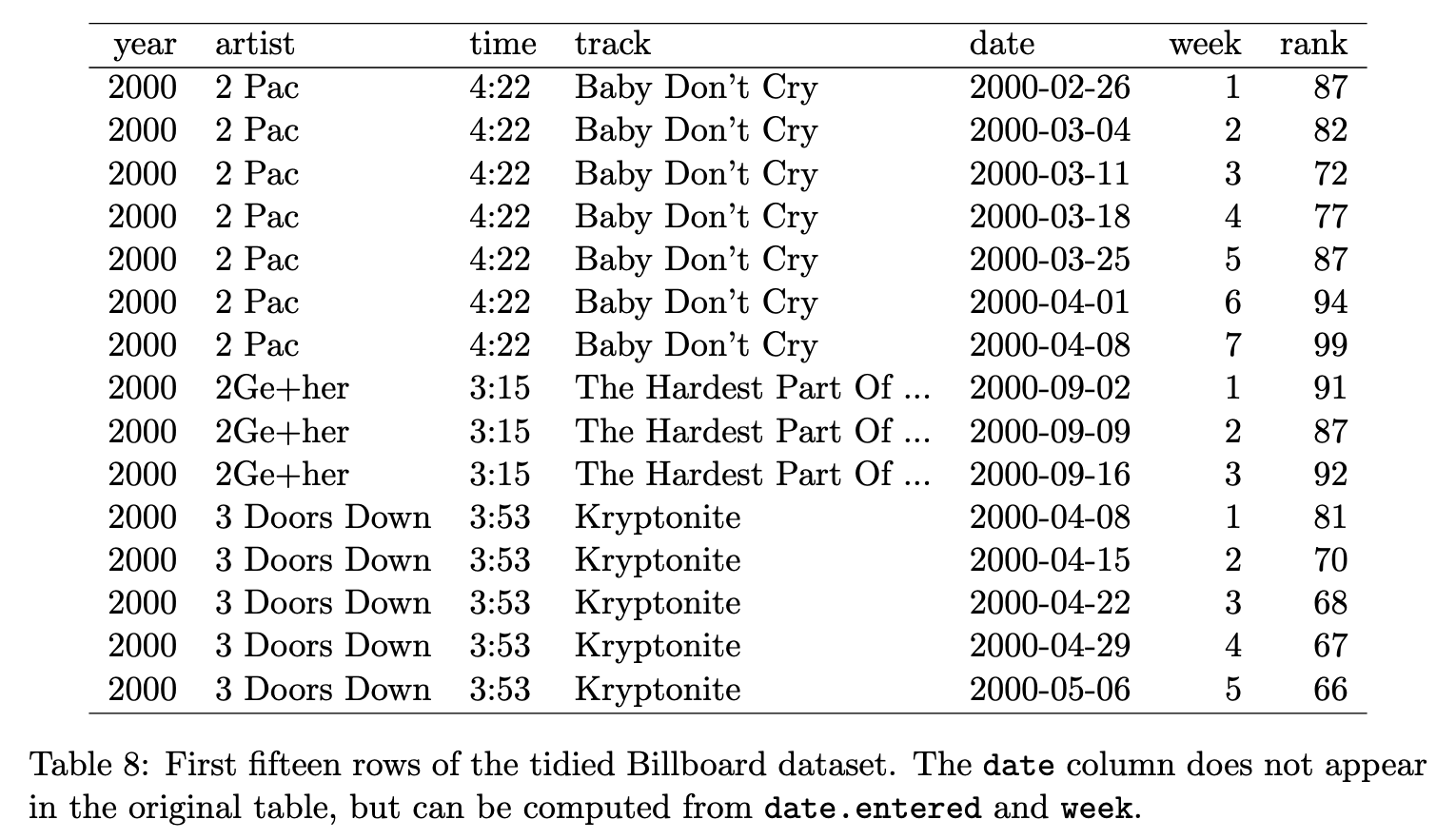
✅ Yes, because 1) The variables are: year, artist, time, track, date, week, and rank, 2) The observation is a recorded rank of a song in a particular week
Is this tidy? (5/8)
Number of cases of TB (tuberculosis)
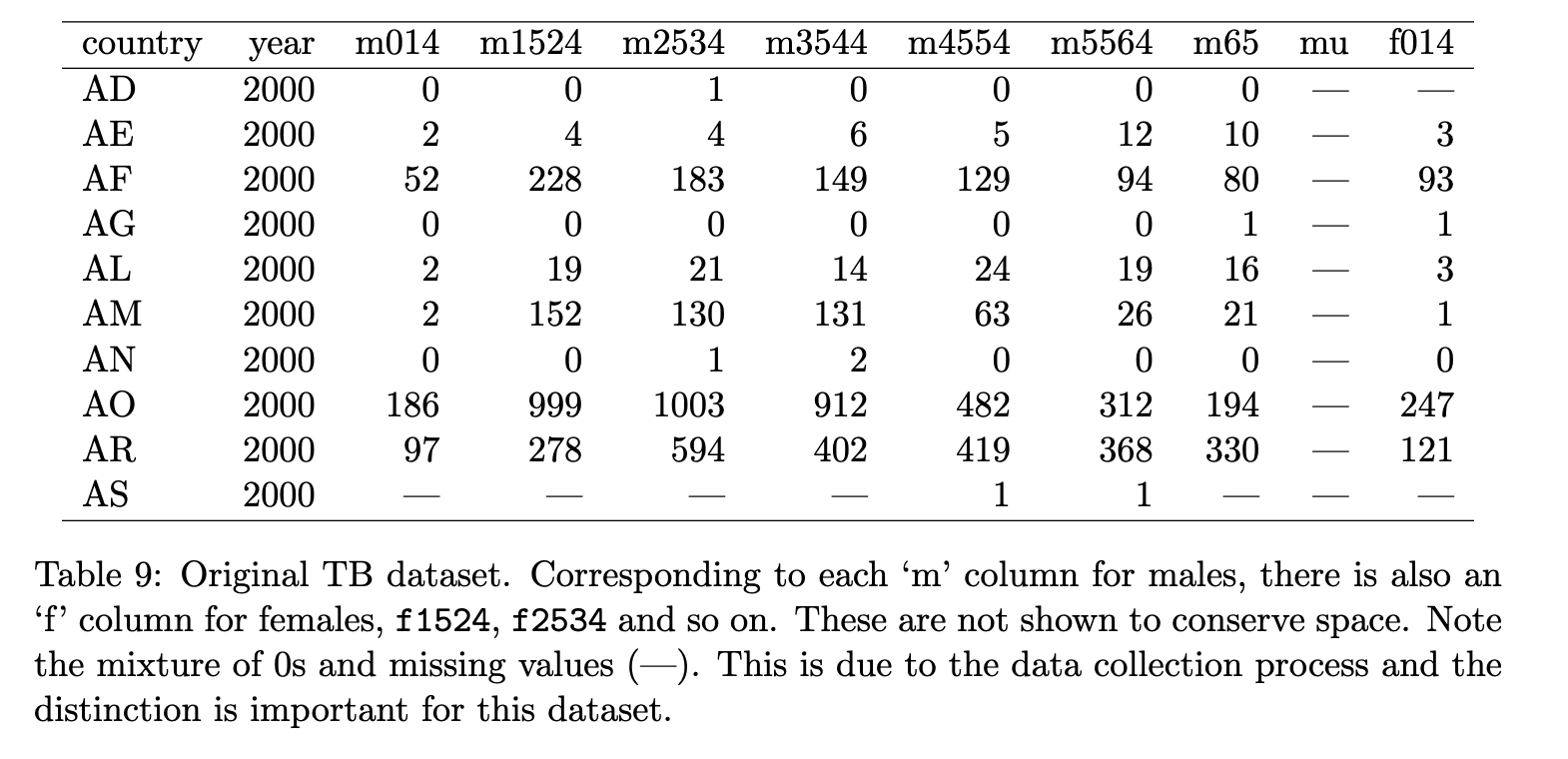
Some information: m014 means for male, 1-14 year old, m1524 means for male 15-24 year old, etc.
❌ No, because the column names contain multiple variable names: gender (m/f) and age (both lower end and higher end of the range).
Is this tidy? (6/8)
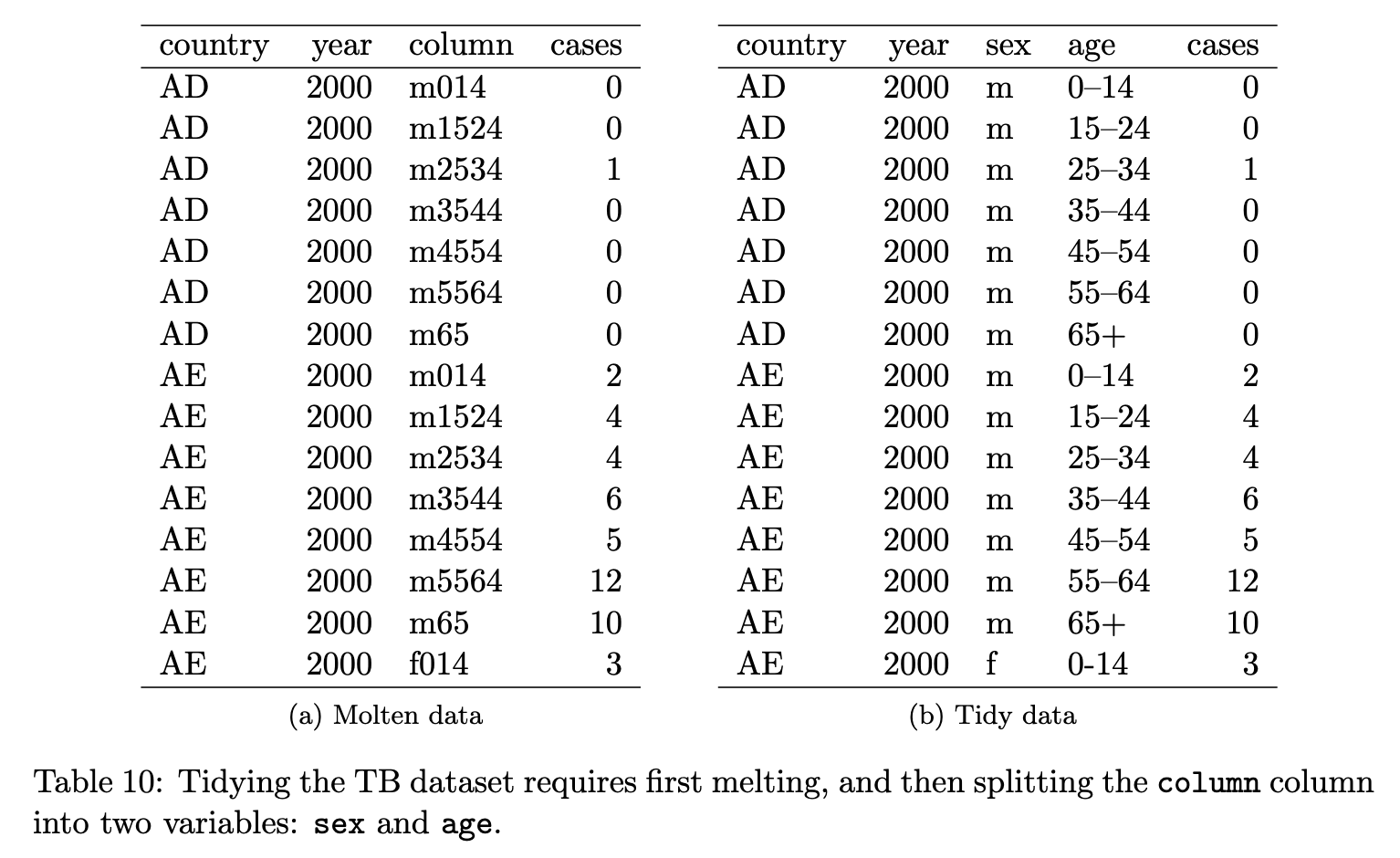
✅ Yes, because 1) The variables are: country, year, column, and cases, and 2) the observation is the number of cases per year, per gender age group, per country
Both are tidy data - you will learn in week 4 how to clean it from (a) to (b)