Elements of Data Science
SDS 322E
Tidy data

- Each variable is a column
- Each observation is a row
- Each cell is a single value
Is this tidy?
The Billboard dataset: the date a song first entered the Billboard Top 100
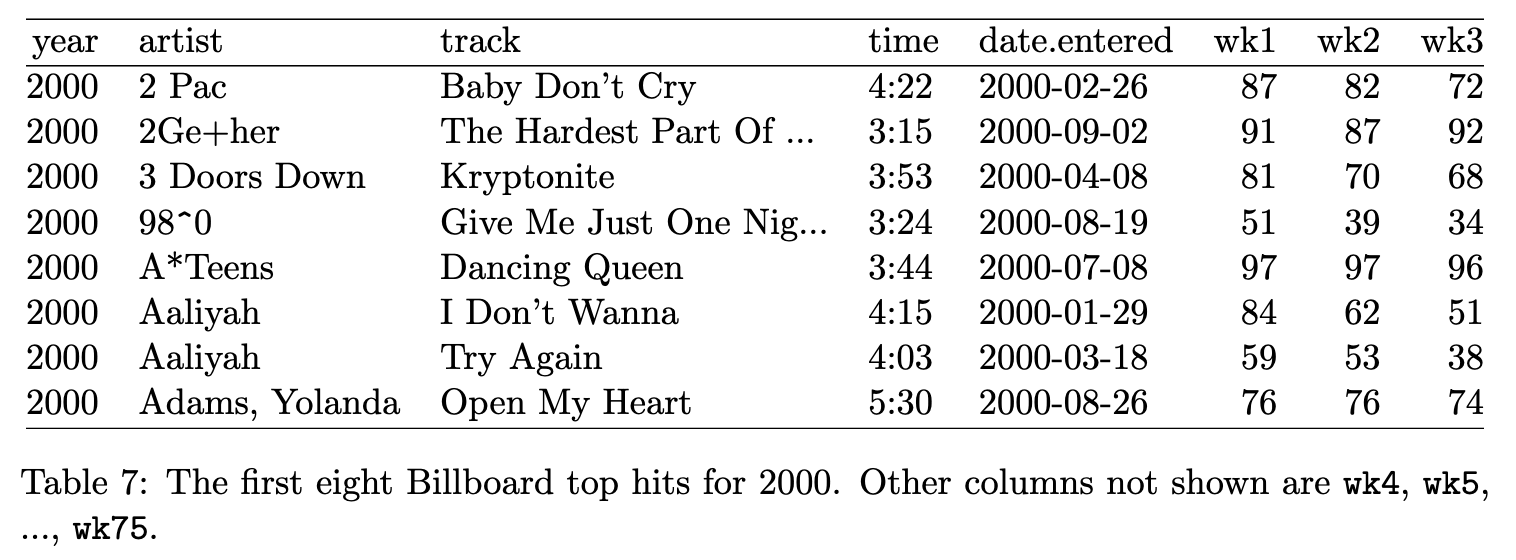
❌: No, because wk1, wk2, … are values, not variables - they should be recorded in cells rather than in column names
Is this tidy?
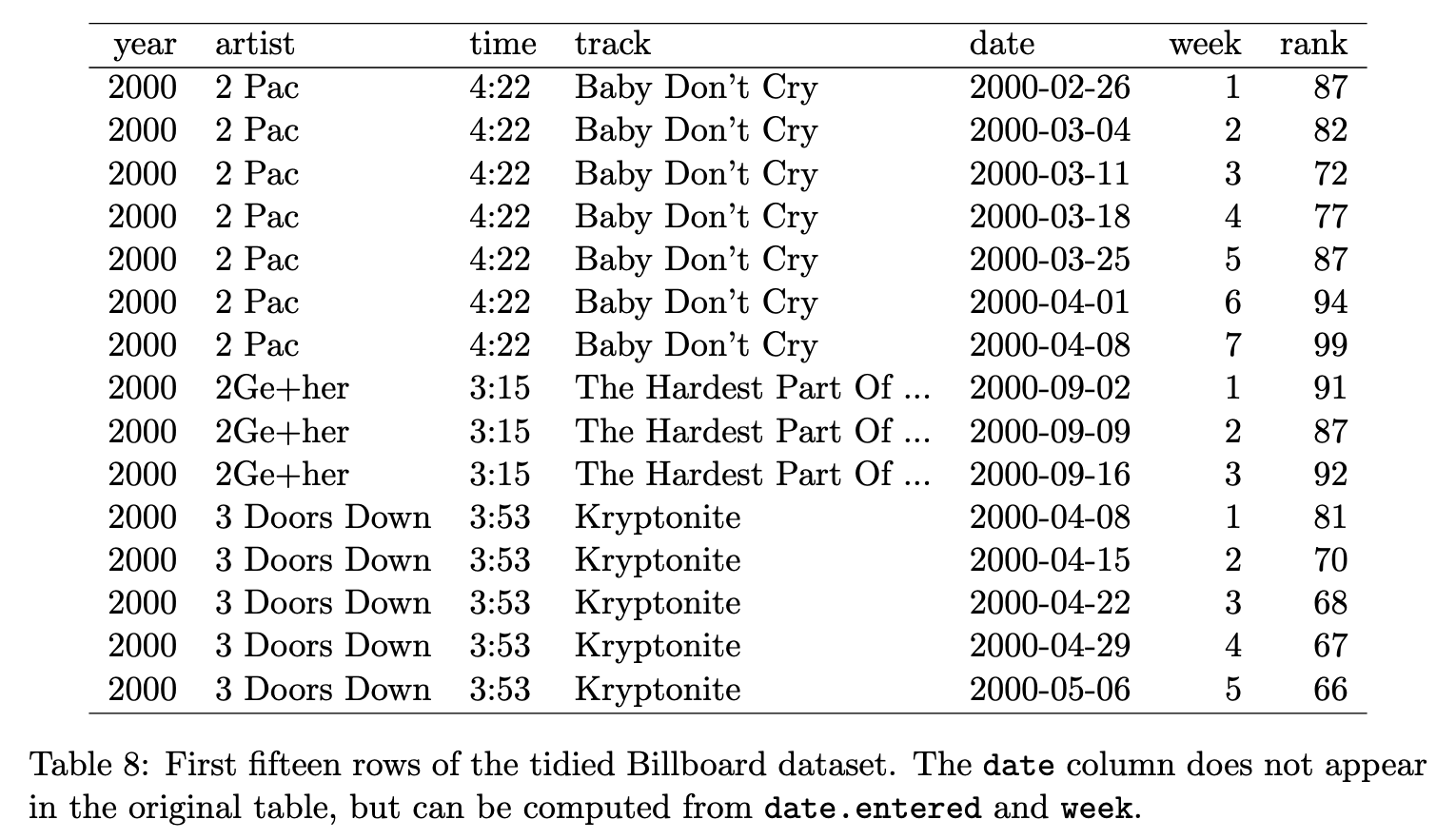
✅ Yes, because 1) The variables are: year, artist, time, track, date, week, and rank, 2) The observation is a recorded rank of a song in a particular week
Pivot longer
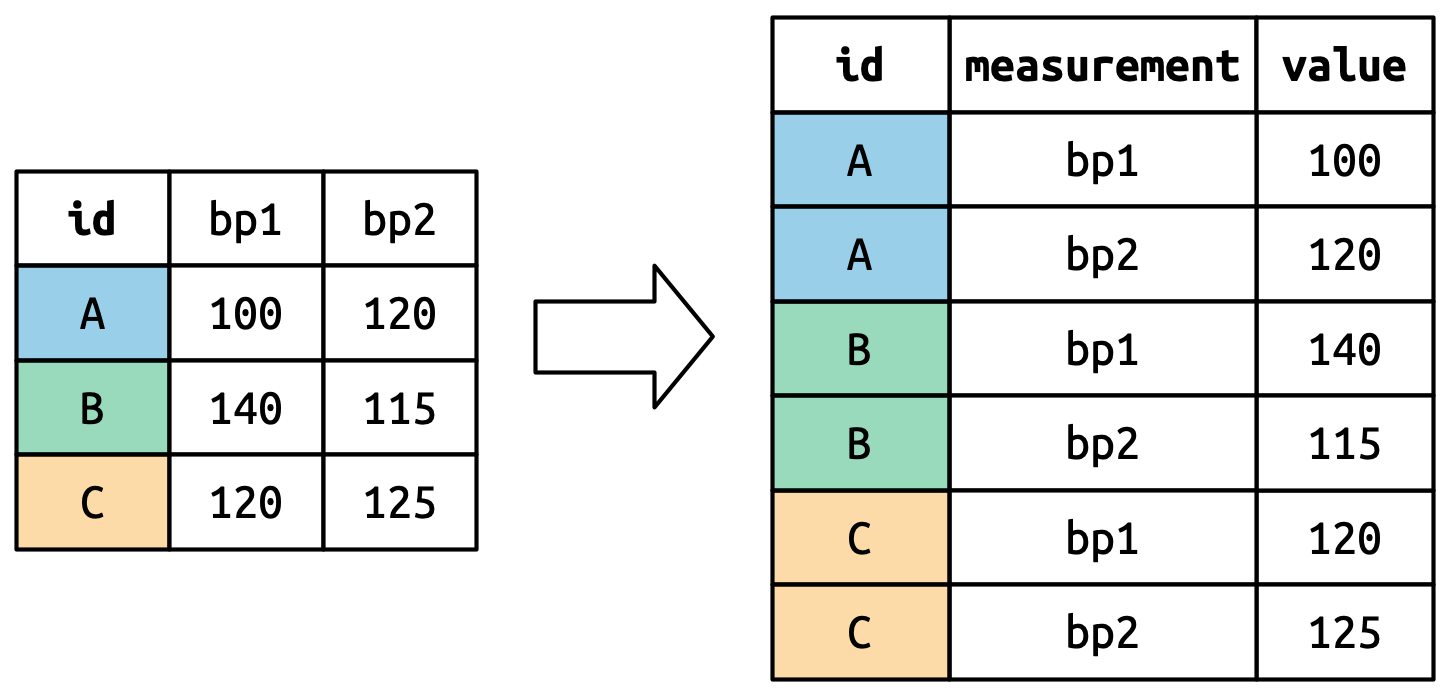
Pivot longer
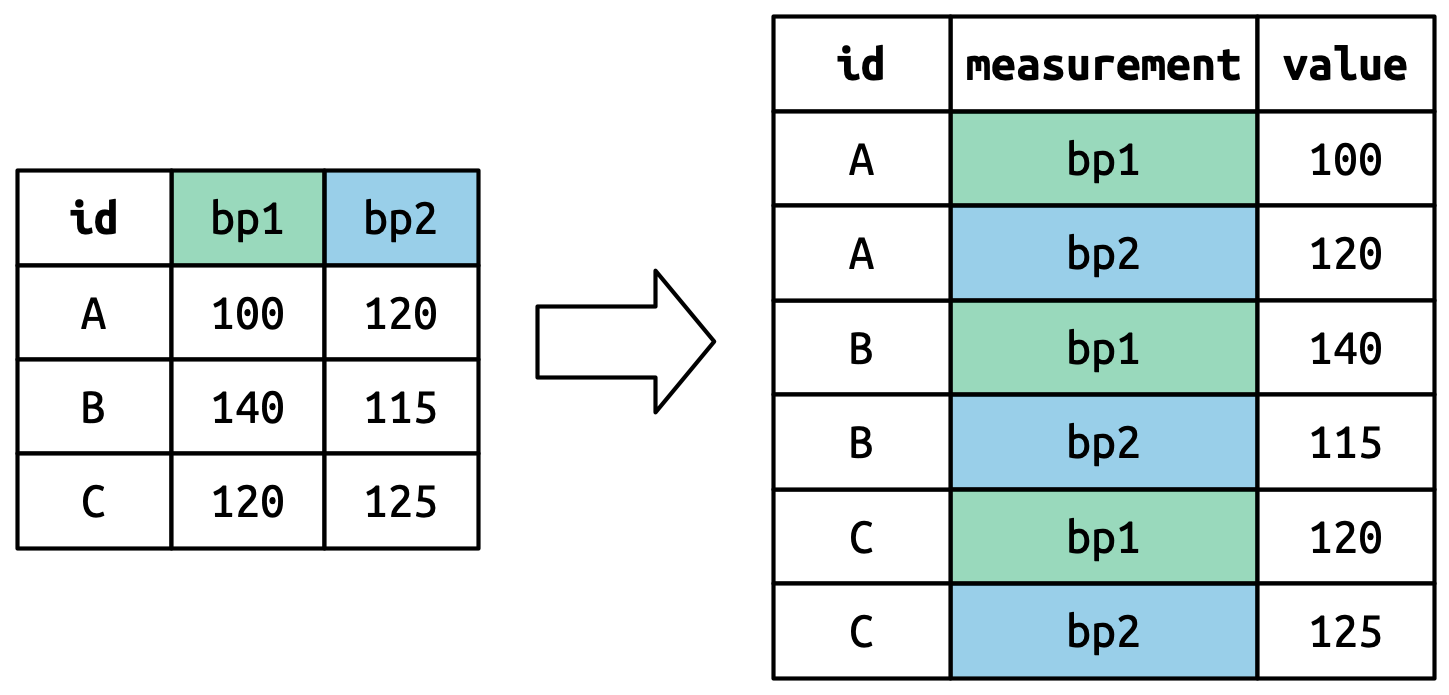
Pivot longer
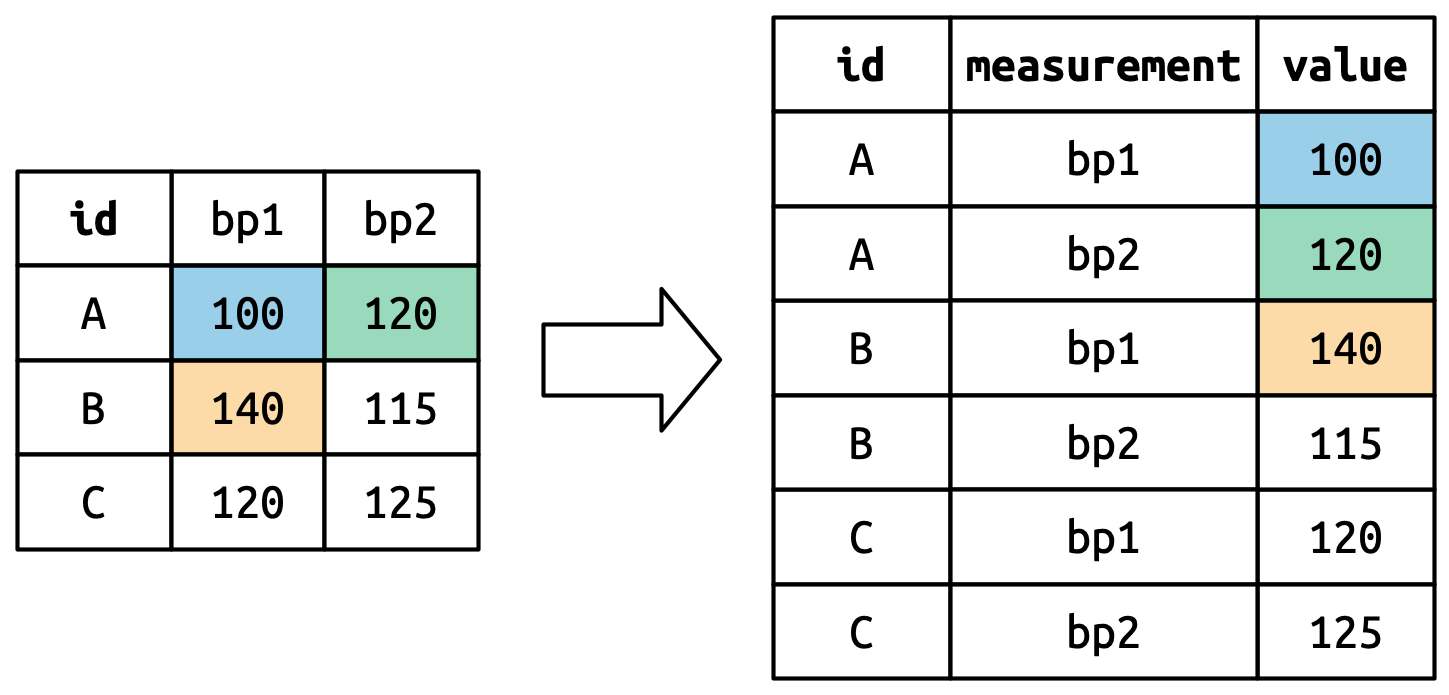
Recall from visualization lecture 1 …
Anscombe’s quartet
x1 x2 x3 x4 y1 y2 y3 y4
1 10 10 10 8 8.04 9.14 7.46 6.58
2 8 8 8 8 6.95 8.14 6.77 5.76
3 13 13 13 8 7.58 8.74 12.74 7.71
4 9 9 9 8 8.81 8.77 7.11 8.84
5 11 11 11 8 8.33 9.26 7.81 8.47
6 14 14 14 8 9.96 8.10 8.84 7.04
7 6 6 6 8 7.24 6.13 6.08 5.25
8 4 4 4 19 4.26 3.10 5.39 12.50
9 12 12 12 8 10.84 9.13 8.15 5.56
10 7 7 7 8 4.82 7.26 6.42 7.91
11 5 5 5 8 5.68 4.74 5.73 6.89Summary of average for x and y:
# A tibble: 4 × 3
set mean_y mean_x
<chr> <dbl> <dbl>
1 1 7.50 9
2 2 7.50 9
3 3 7.5 9
4 4 7.50 9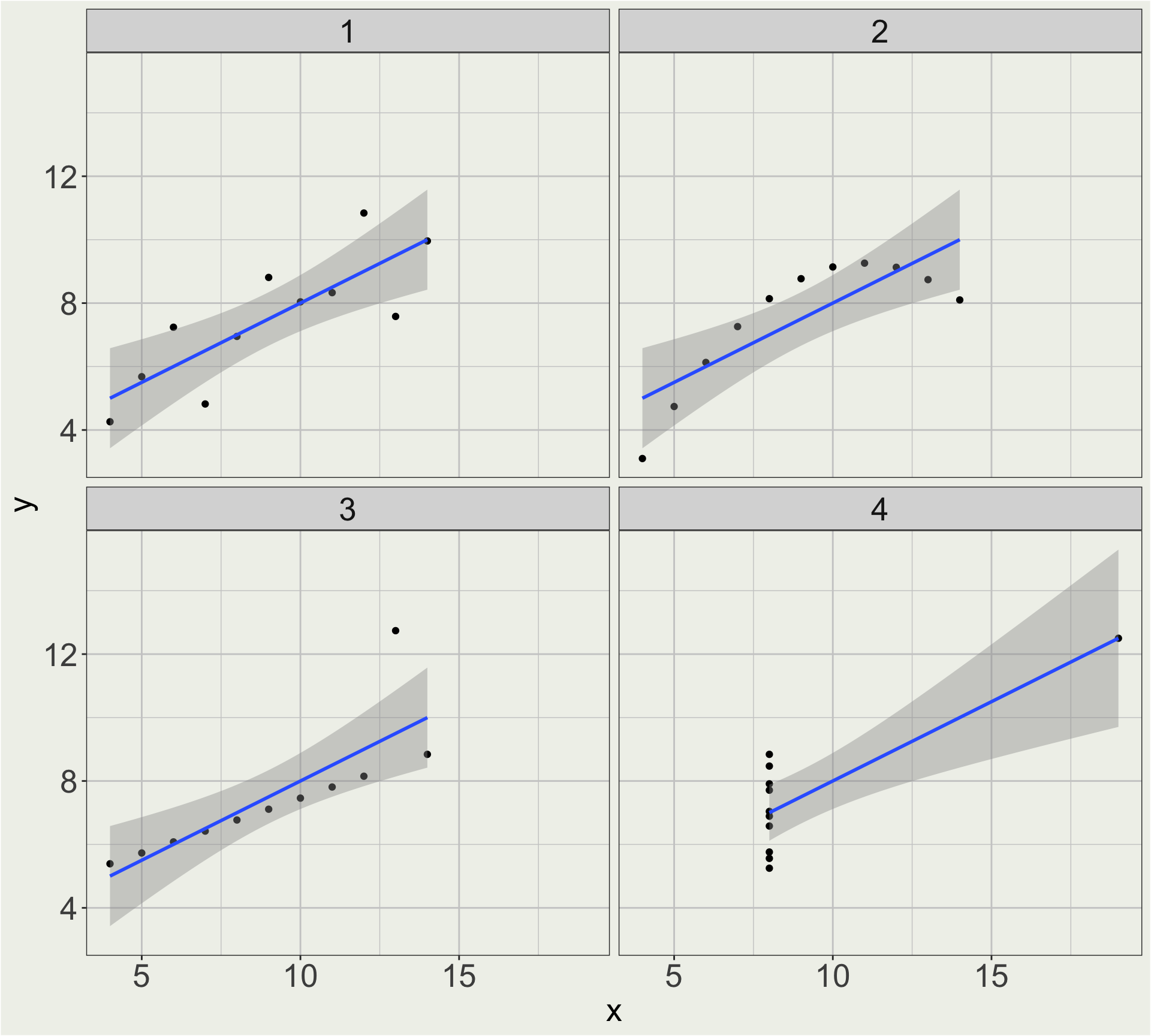
Combine pivot_longer and pivot_wider
If we can structure the data into this format…
# A tibble: 44 × 3
set x y
<chr> <dbl> <dbl>
1 1 10 8.04
2 2 10 9.14
3 3 10 7.46
4 4 8 6.58
5 1 8 6.95
6 2 8 8.14
7 3 8 6.77
8 4 8 5.76
9 1 13 7.58
10 2 13 8.74
# ℹ 34 more rowsthen it is easy to map them into x and y axes and facet by set.
Combine pivot_longer and pivot_wider
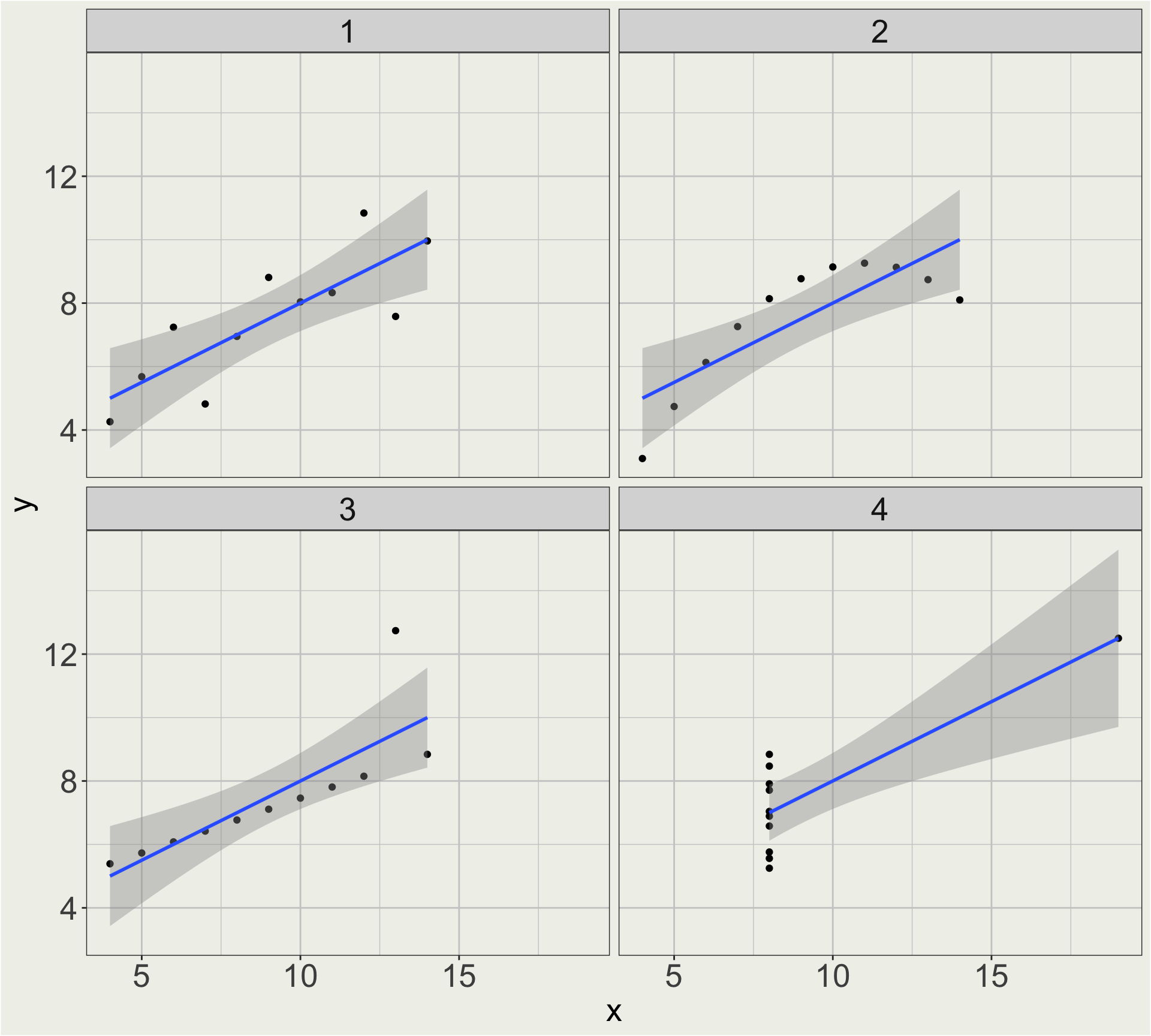
Now plot the data!
dt2 <- dt |>
pivot_longer(cols = x1: y4, names_to = "variable", values_to = "value") |>
separate(variable, into = c("type", "set"), sep = 1) |>
pivot_wider(names_from = type, values_from = value)
dt2 |>
ggplot(aes(x = x, y = y)) +
geom_point() +
geom_smooth(method = "lm") +
facet_wrap(vars(set), ncol = 2) 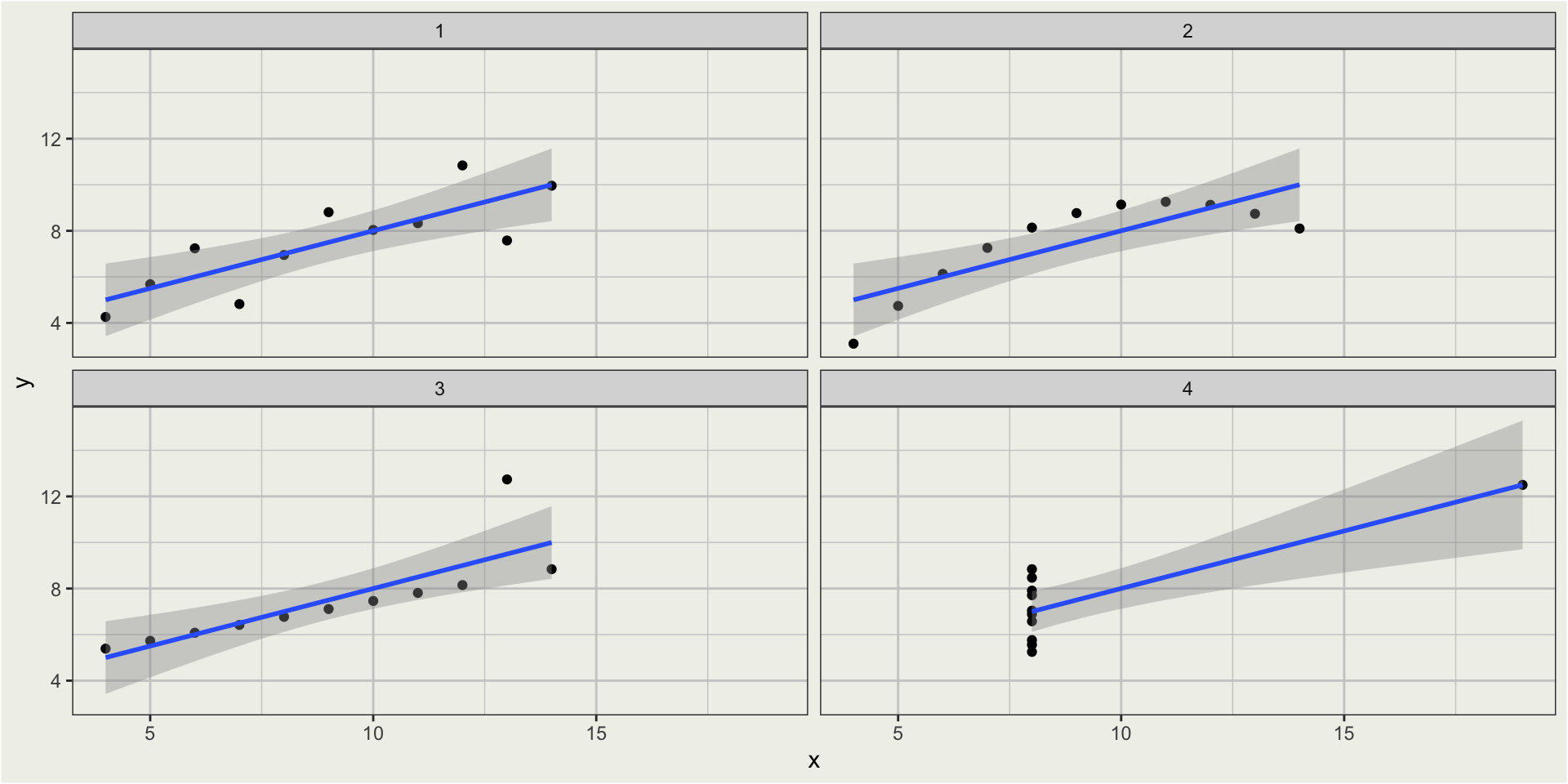
Bonus: plot flight origin and destination on the map
Let’s plot all the origin and destination airports of all the flights in nycflights13::flights on the US map.