The output from flights |> filter(month == 1) is a tibble, which is the first argument for select(). We can put it in the front of the function.
Think of it as we take the flight data, filter it by month == 1, and then select the variables month, day, and year from the filtered data.
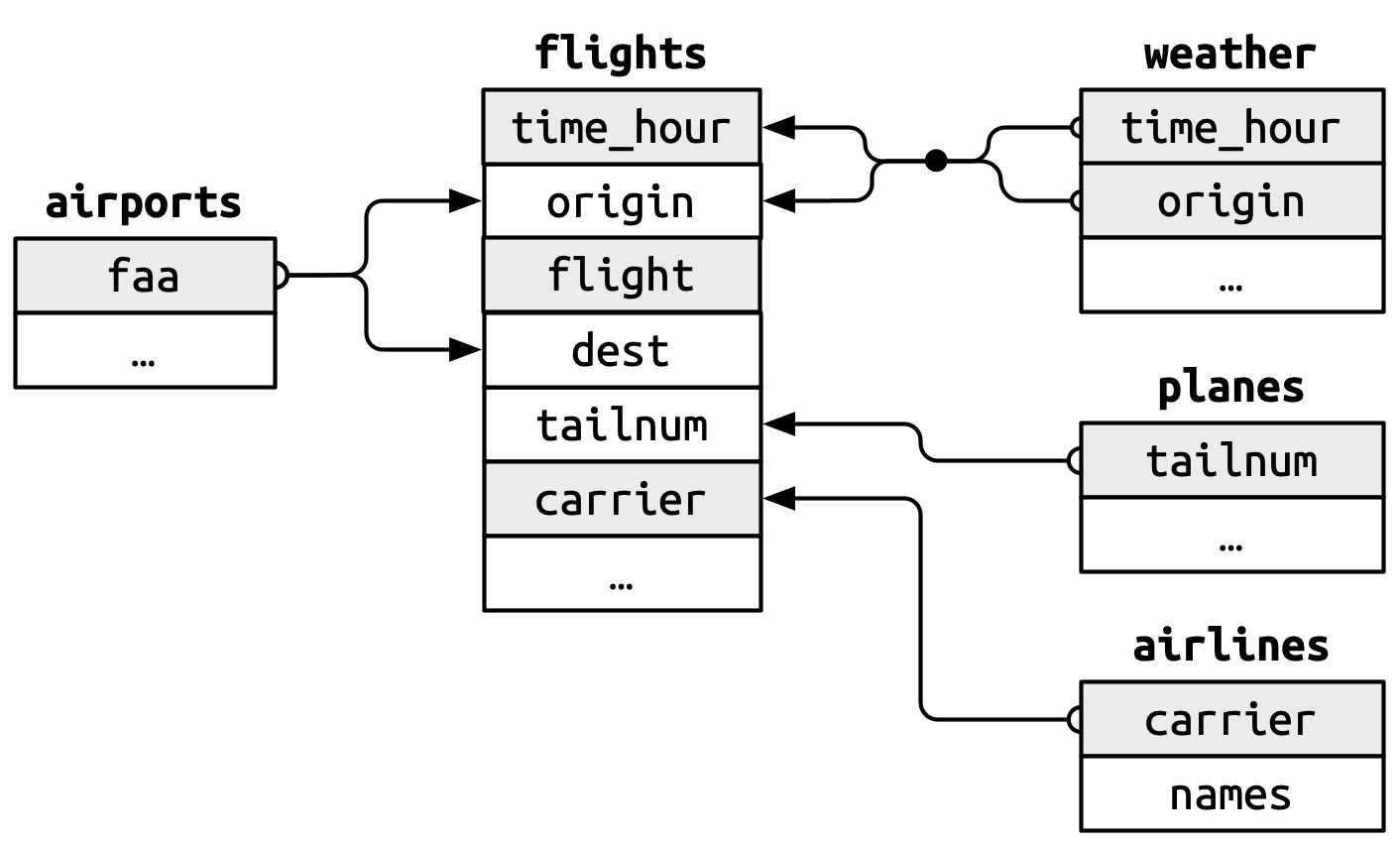
Different types of join
Mutate join
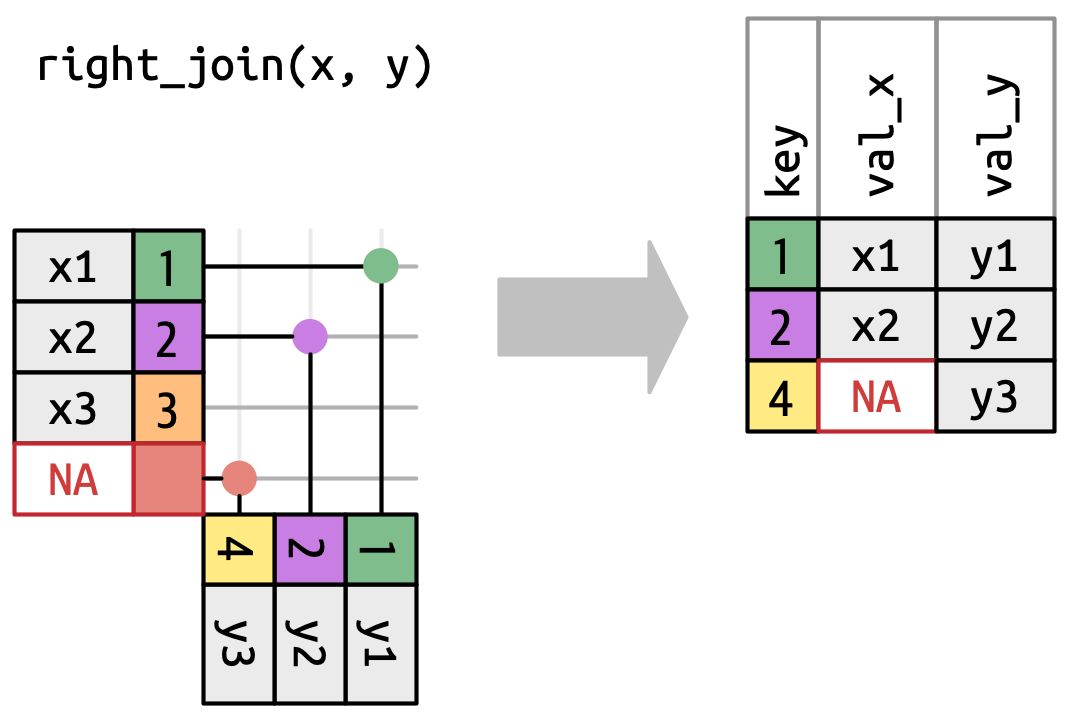
Left join: left_join()
Right join: right_join()
Inner join: inner_join()
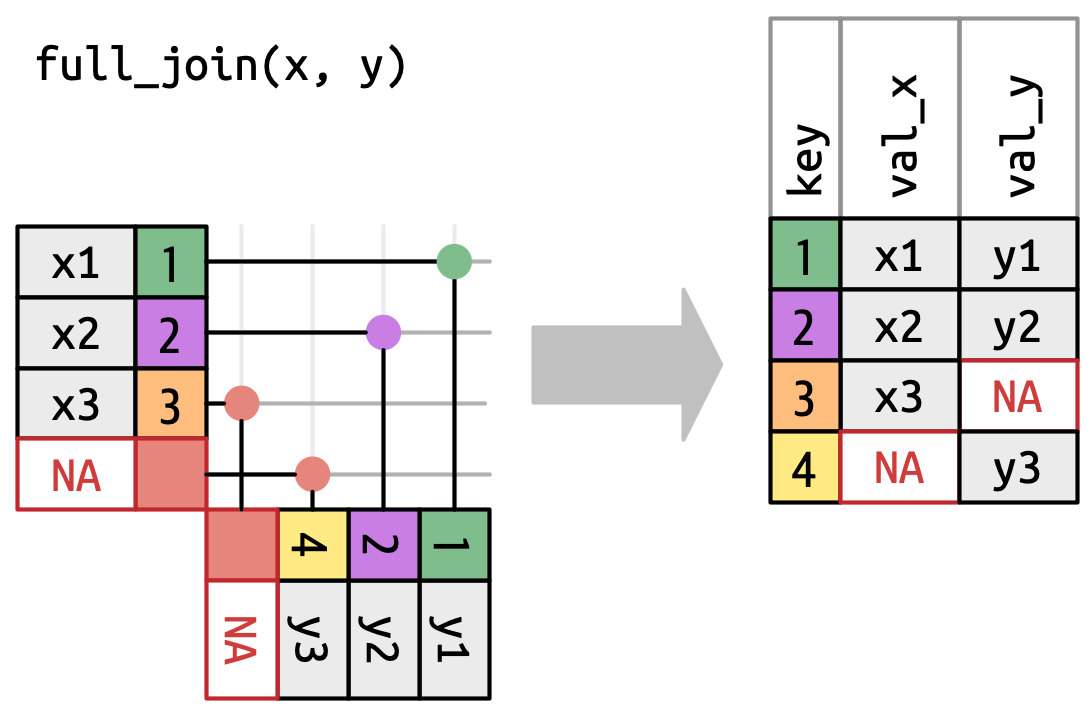
Full join: full_join()
Filter join
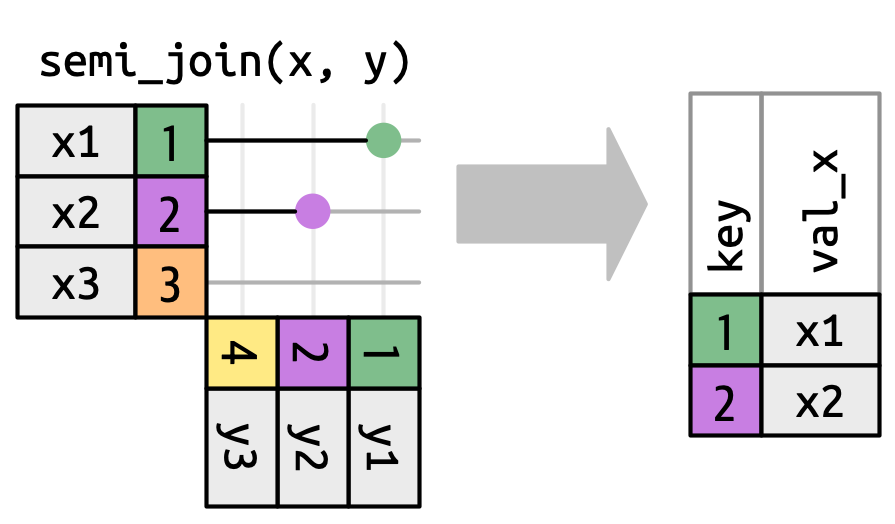
Semi join: semi_join()
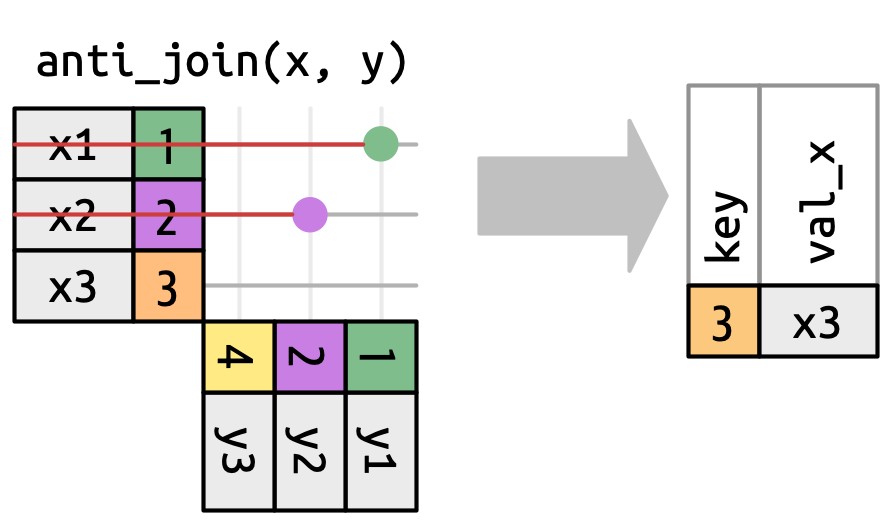
Anti join: anti_join()
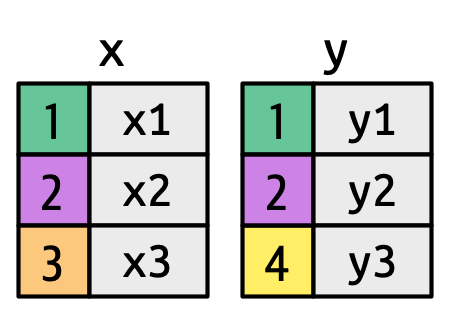
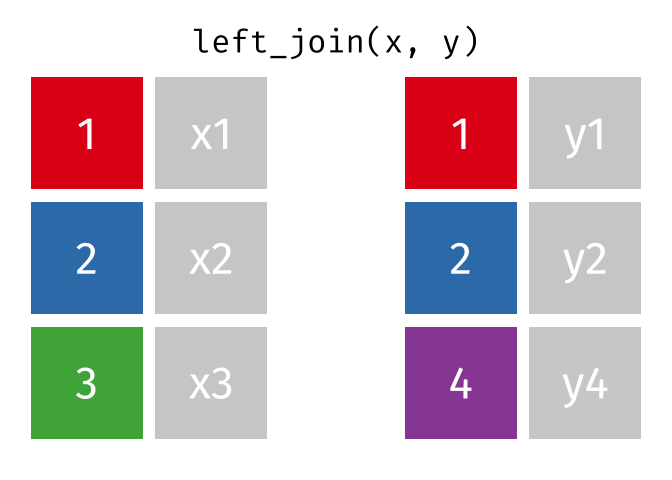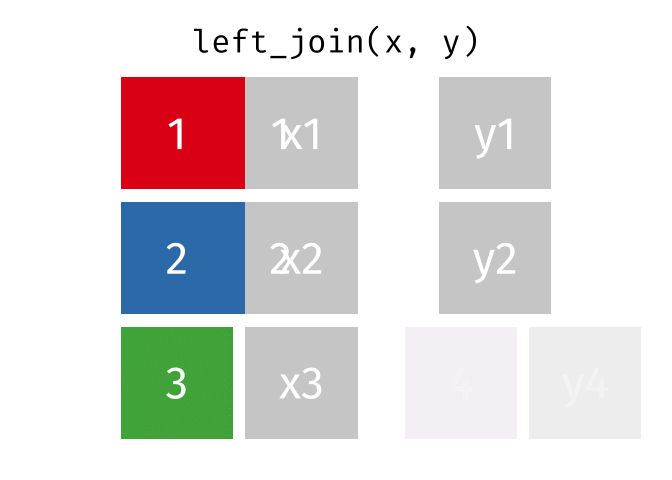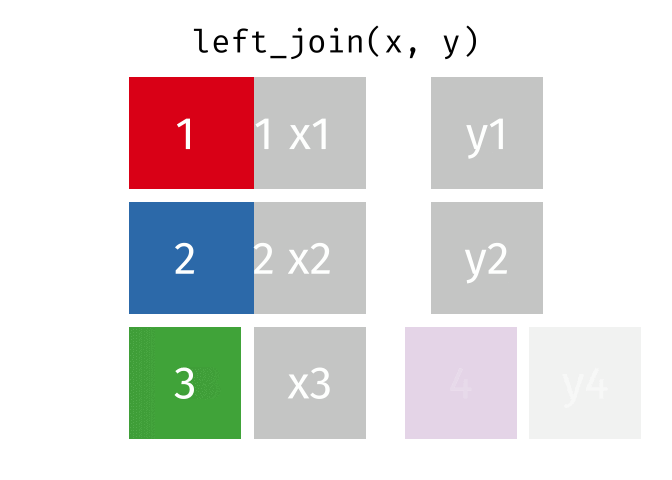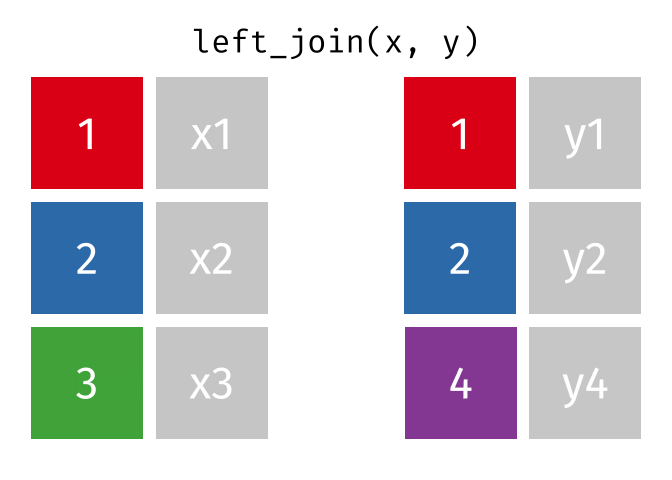
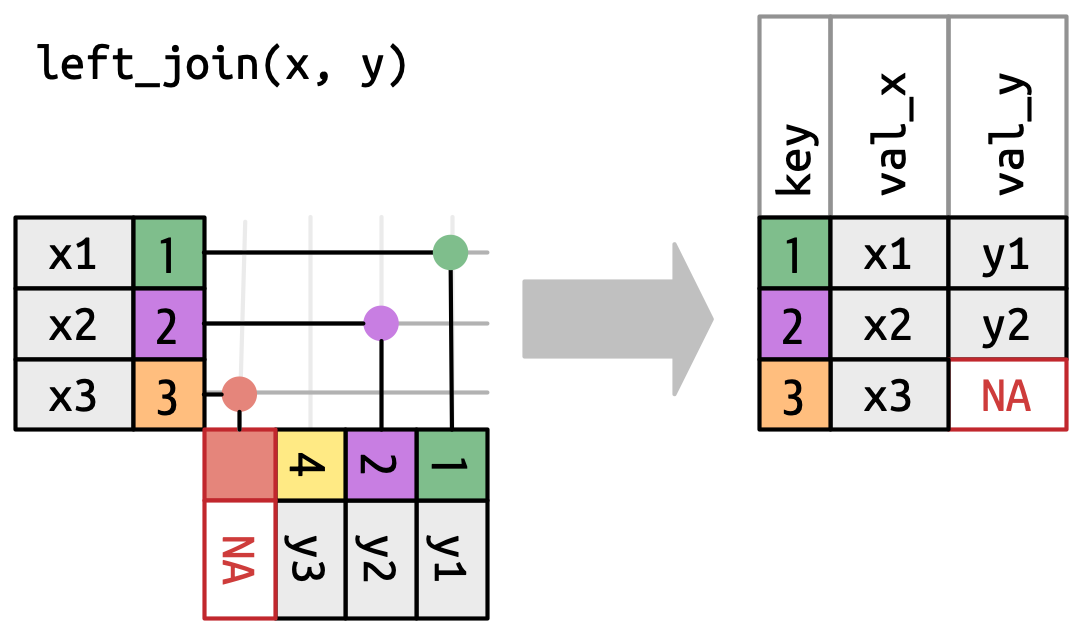
Left join
A left join keeps all observations in data frame x. Every row of x is preserved in the output and NA is used if there is no matching value in data frame y.
Left join syntax (1/2)
left_join(DATA_X, DATA_Y, by = "SHARED_KEY")
df1 <-tibble(x =c(1, 2, 3), y =c("a", "b", "c"))df1
# A tibble: 3 × 2
x y
<dbl> <chr>
1 1 a
2 2 b
3 3 c
df2 <-tibble(x =c(1, 2, 4), z =c("d", "e", "f"))df2
# A tibble: 3 × 2
x z
<dbl> <chr>
1 1 d
2 2 e
3 4 f
left_join(df1, df2, by ="x")
# A tibble: 3 × 3
x y z
<dbl> <chr> <chr>
1 1 a d
2 2 b e
3 3 c <NA>
Other variations:
# you can use pipedf1 |>left_join(df2, by ="x")# auto-detect if the key variable has the# same name df1 |>left_join(df2)# some textbooks will use `join_by()`# join_by() is powerful for non-equi joins# we won't cover non-equi joins in this classdf1 |>left_join(df2, join_by("x"))
Left join syntax (2/2)
When the key variables have different names in the two data frames, you need to specify the names of the key variables in both data frames.
left_join(DATA_X, DATA_Y, by = c("KEY_IN_X" = "KEY_IN_Y"))
df3 <-tibble(x1 =c(1, 2, 3), y =c("a", "b", "c"))df3
# A tibble: 3 × 2
x1 y
<dbl> <chr>
1 1 a
2 2 b
3 3 c
df4 <-tibble(x2 =c(1, 2, 4), z =c("d", "e", "f"))df4
# A tibble: 3 × 2
x2 z
<dbl> <chr>
1 1 d
2 2 e
3 4 f
left_join(df3, df4, by =c("x1"="x2"))
# A tibble: 3 × 3
x1 y z
<dbl> <chr> <chr>
1 1 a d
2 2 b e
3 3 c <NA>
Other variations:
# pipe still worksdf3 |>left_join(df4, by =c("x1"="x2")) # the `join_by()` syntax is more complicated # (you need "==" here)df3 |>left_join(df4, join_by("x1"=="x2"))
Auto-detect won’t work if the key variables have different names.
# A tibble: 3 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 ZWU Washington Union Station 38.9 -77.0 76 -5 A America/New_York
2 ZYP Penn Station 40.8 -74.0 35 -5 A America/New_York
3 BQN Rafael Hernández Airport 18.5 -67.1 49 -4 A America/Puerto_R…
flights_tiny |>left_join(all_airports, by =c("dest"="faa"))
# A tibble: 5 × 14
month day hour origin dest tailnum carrier name lat lon alt tz
<int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 1 1 5 EWR IAH N14228 UA George… 30.0 -95.3 97 -6
2 1 1 5 LGA IAH N24211 UA George… 30.0 -95.3 97 -6
3 1 1 5 JFK MIA N619AA AA Miami … 25.8 -80.3 8 -5
4 1 1 5 JFK BQN N804JB B6 Rafael… 18.5 -67.1 49 -4
5 1 1 6 LGA ATL N668DN DL Hartsf… 33.6 -84.4 1026 -5
# ℹ 2 more variables: dst <chr>, tzone <chr>
Your time - pipe
Without running the code, guess whether the following code will work.
Part 1
select() is a function from the dplyr package that keeps (drops) columns from a data frame.
A left join keeps all observations in x. Every row of x is preserved in the output and NA is used if there is no matching value in y.
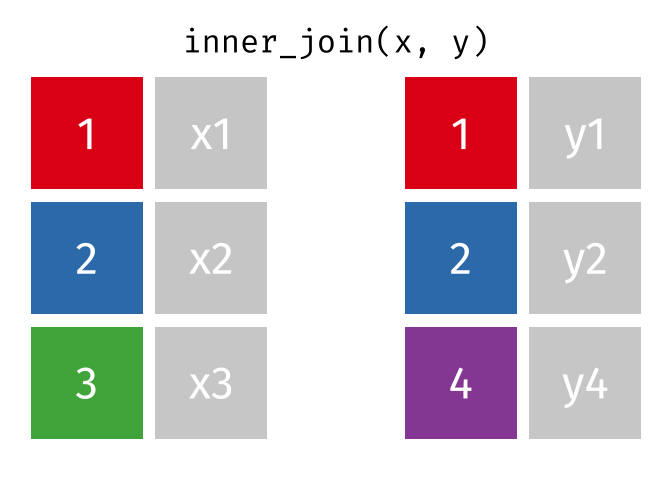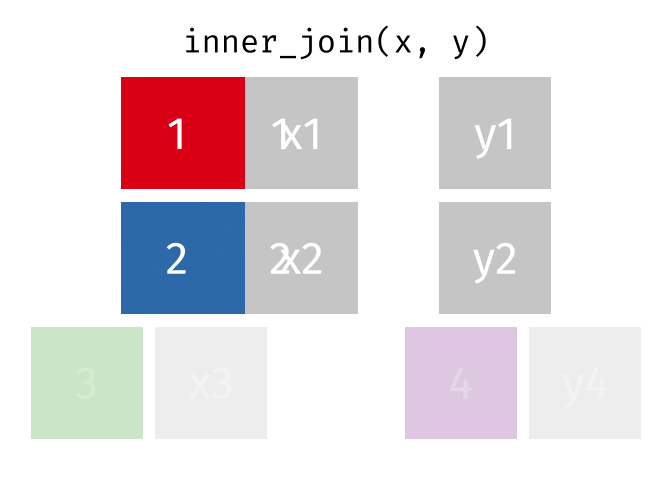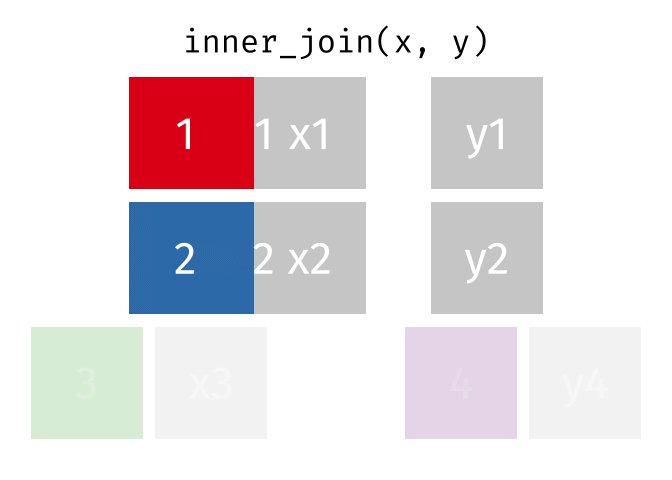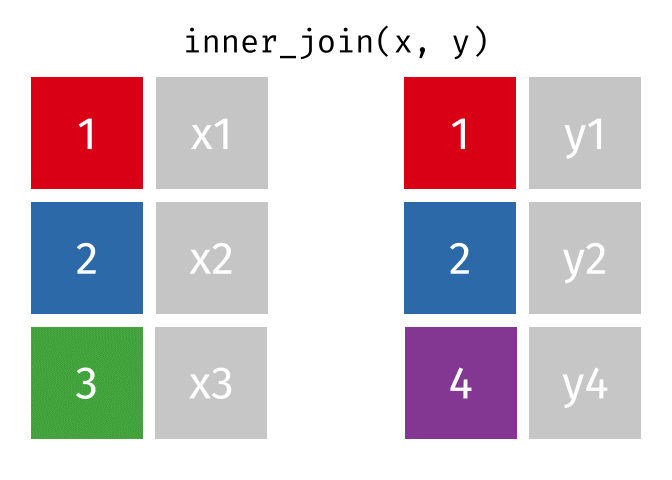
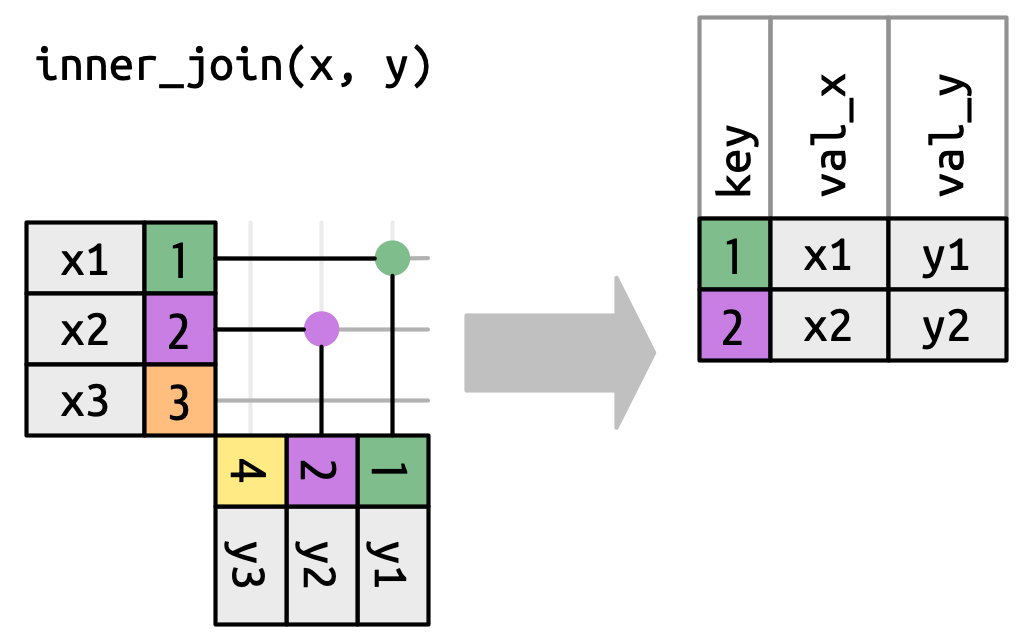
An inner join retained the rows if and only if the keys are equal.
Inner join with the flight data
What would you expect the result to be if we do an inner join rather than left join?
flights_tiny
# A tibble: 5 × 7
month day hour origin dest tailnum carrier
<int> <int> <dbl> <chr> <chr> <chr> <chr>
1 1 1 5 EWR IAH N14228 UA
2 1 1 5 LGA IAH N24211 UA
3 1 1 5 JFK MIA N619AA AA
4 1 1 5 JFK BQN N804JB B6
5 1 1 6 LGA ATL N668DN DL
airports_dest
# A tibble: 3 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 ATL Harts… 33.6 -84.4 1026 -5 A Amer…
2 IAH Georg… 30.0 -95.3 97 -6 A Amer…
3 MIA Miami… 25.8 -80.3 8 -5 A Amer…
flights_tiny |>inner_join(airports_dest, by =c("dest"="faa"))
# A tibble: 4 × 14
month day hour origin dest tailnum carrier name lat lon alt tz
<int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 1 1 5 EWR IAH N14228 UA George… 30.0 -95.3 97 -6
2 1 1 5 LGA IAH N24211 UA George… 30.0 -95.3 97 -6
3 1 1 5 JFK MIA N619AA AA Miami … 25.8 -80.3 8 -5
4 1 1 6 LGA ATL N668DN DL Hartsf… 33.6 -84.4 1026 -5
# ℹ 2 more variables: dst <chr>, tzone <chr>
Only the four rows that have a match in the airports_dest data are kept.
Other joins
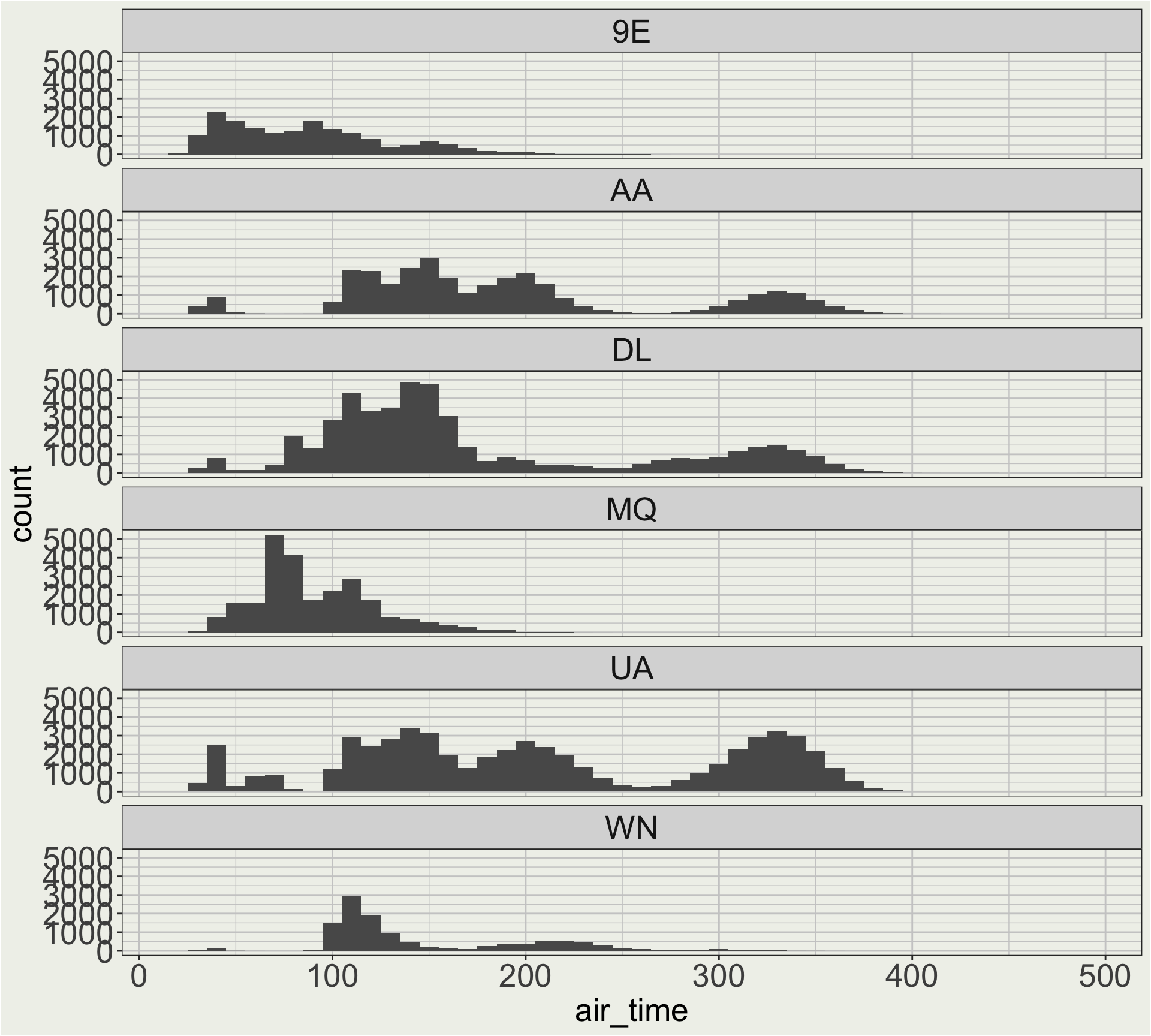
Application 1a: distribution of air time of flights
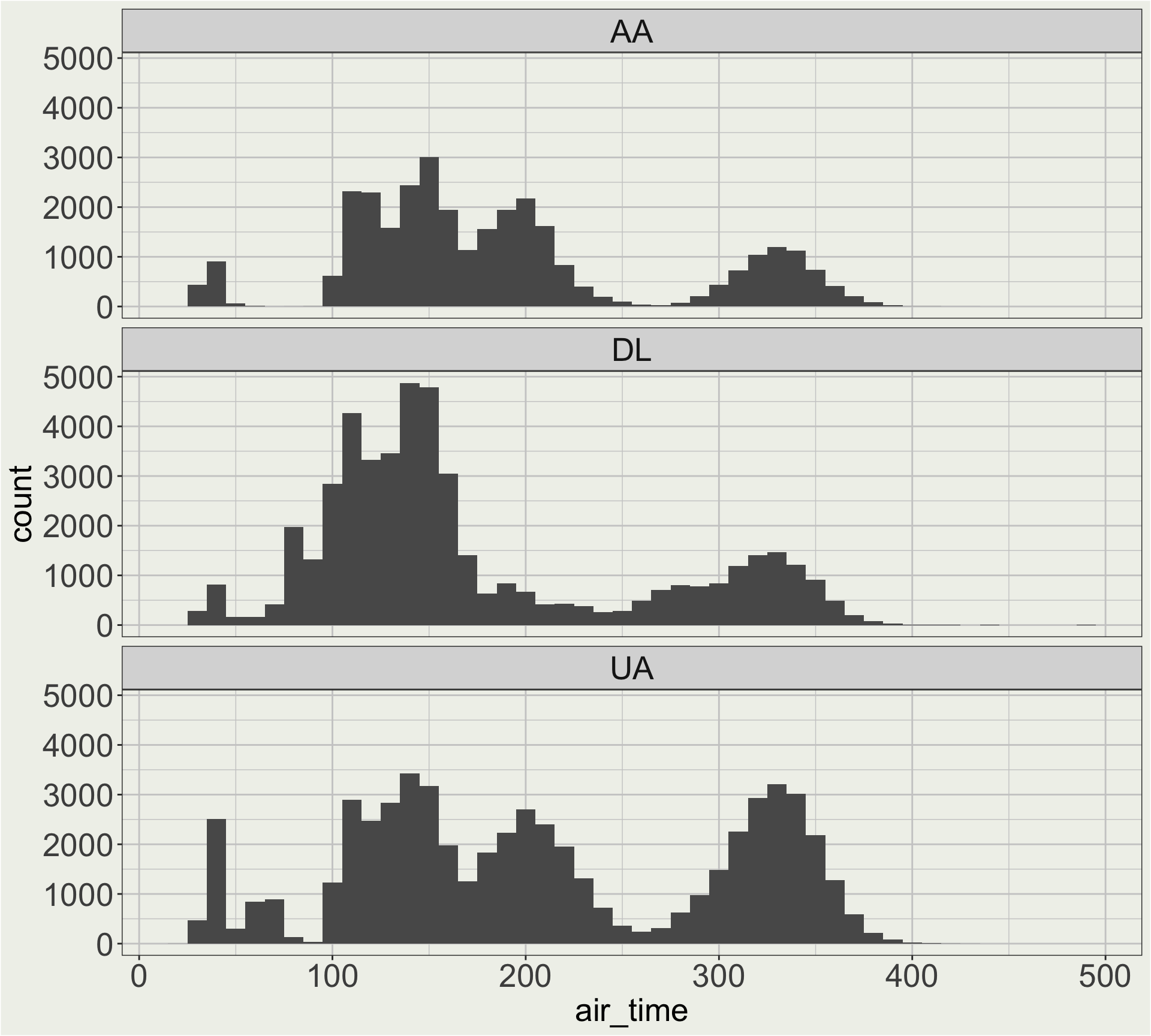
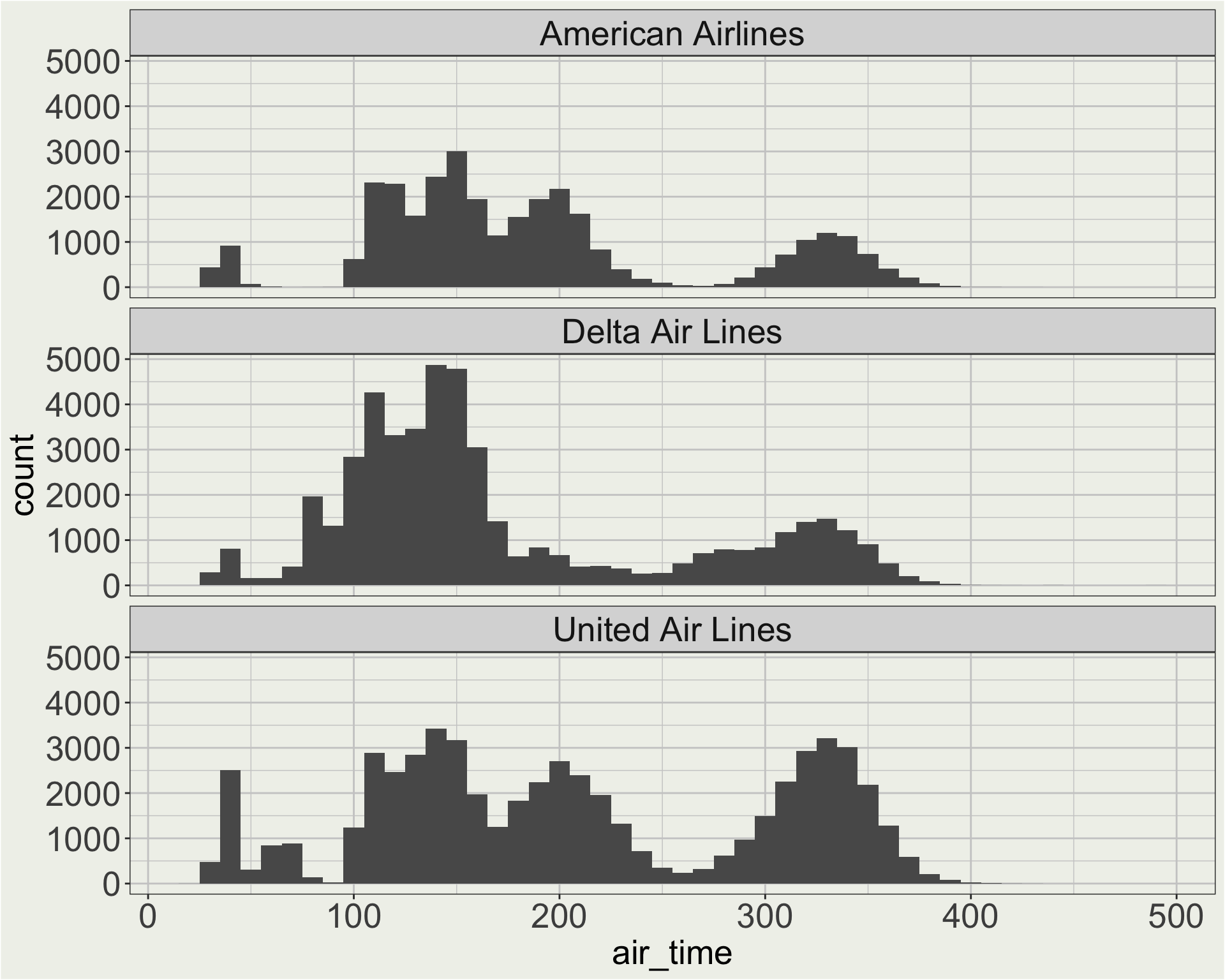
What is the distribution of air time for all flights in the flights data?
How does the distribution of air time vary by carrier?
flights |># we looked in the air_time vs. distance plot# before the there are long flights # thqt go to HNL (Hawaii)filter(dest !="HNL") |>filter(carrier %in%c("AA", "DL", "UA")) |>ggplot(aes(x = air_time)) +geom_histogram(binwidth =10) +facet_wrap(vars(carrier), ncol =1)
Maybe I want a better facet header than “AA”, “DL”, and “UA”. 🤔
Application 1a: use fct_recode to recode carrier names
I didn’t give you can example on fct_recode() but here you go.
flights |># we looked in the air_time vs. distance plot# before the there are long flights # thqt go to HNL (Hawaii)filter(dest !="HNL") |>filter(carrier %in%c("AA", "DL", "UA")) |>mutate(carrier =fct_recode( carrier, "American Airlines"="AA", "Delta Air Lines"="DL", "United Air Lines"="UA")) |>ggplot(aes(x = air_time)) +geom_histogram(binwidth =10) +facet_wrap(vars(carrier), ncol =1)
Often, we make a base plot first (previous page), see somewhere we want to improve (facet header), and then go back to the data wrangling step to make the change (mutate(carrier = fct_recode(...))).
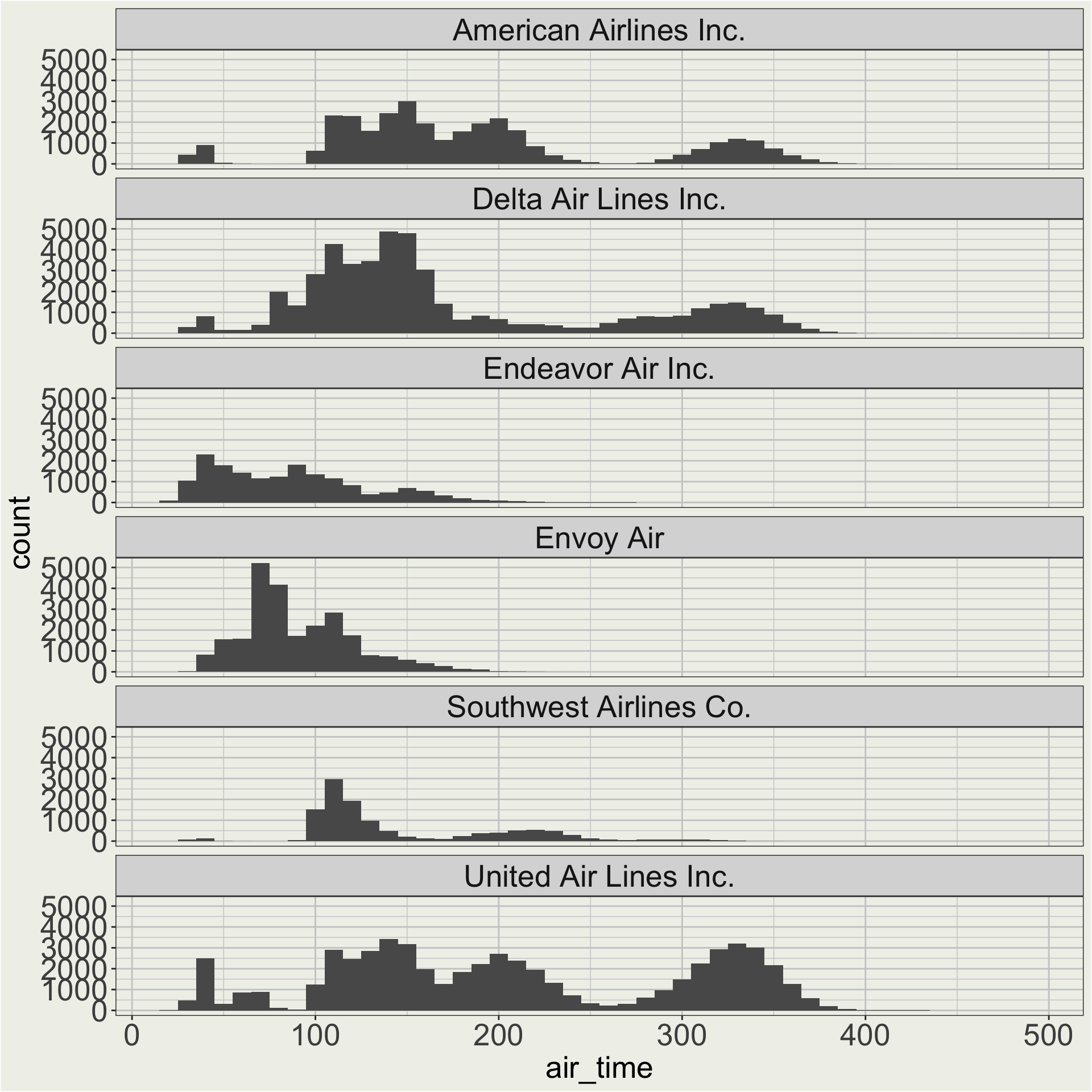
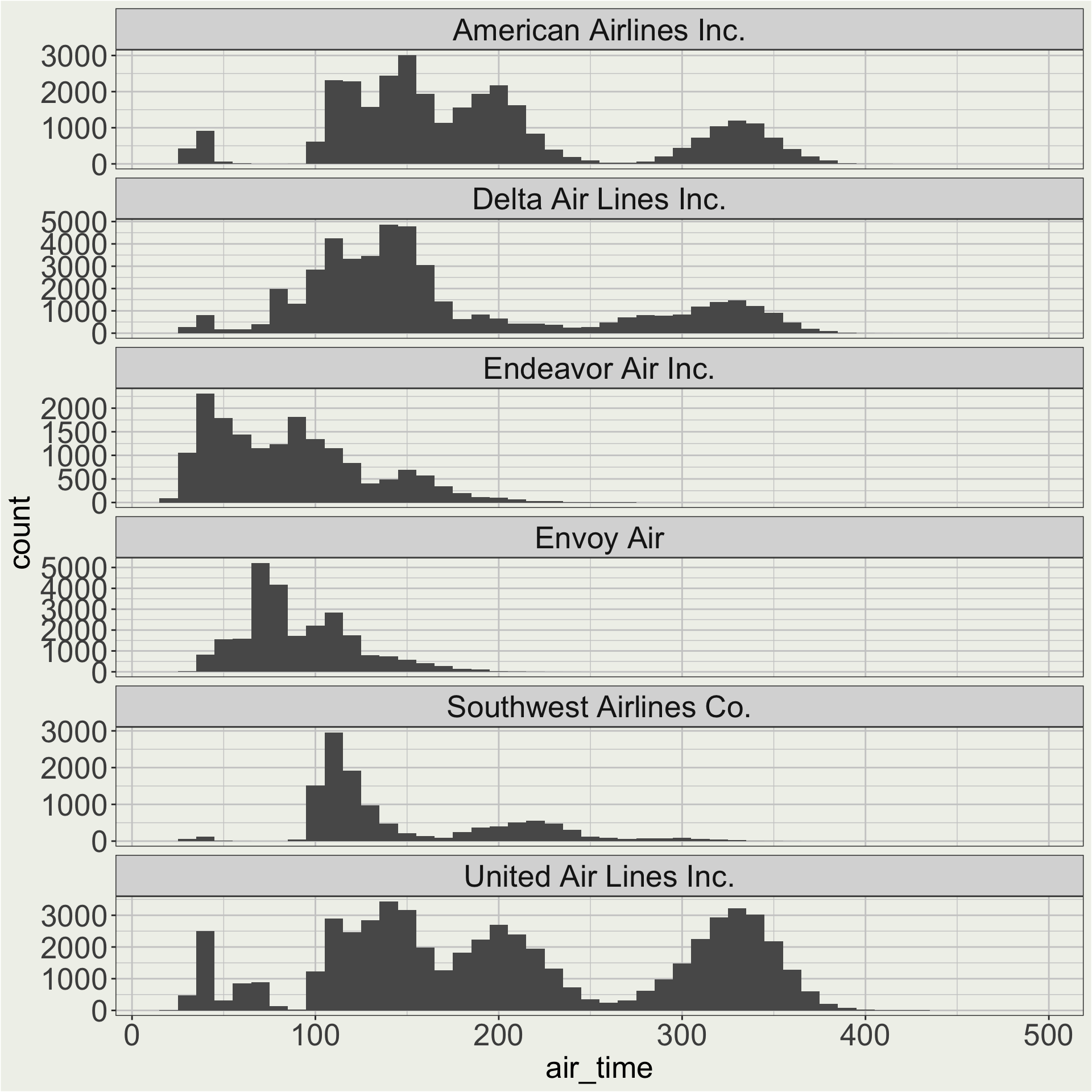
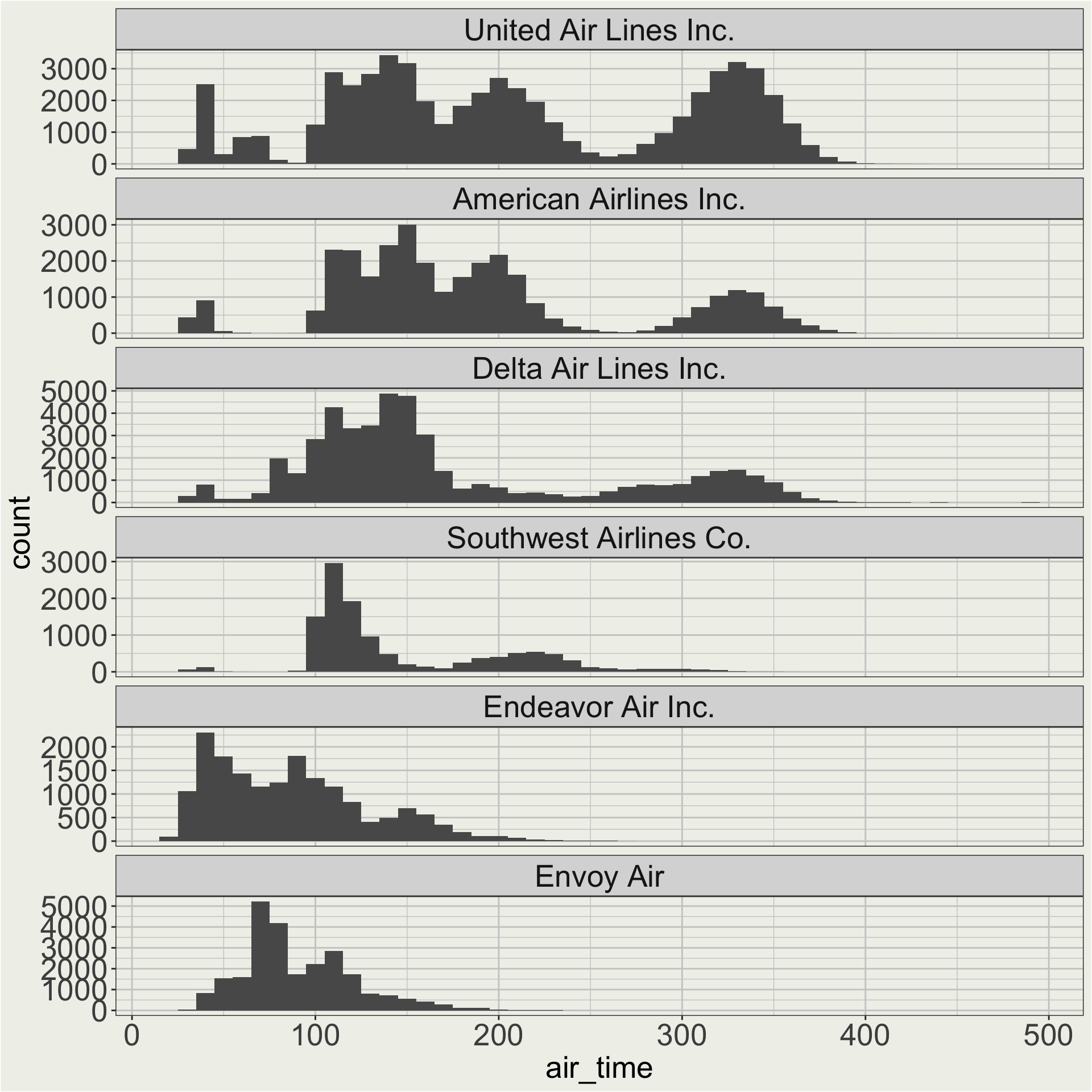
Application 1b: distribution of air time of flights
When we have more carriers, manually recode all the airlines becomes tedious. 🤔