H. Sherry Zhang Department of Statistics and Data Sciences The University of Texas at Austin
Fall 2025
Learning objectives
Understand what problem dimension reduction methods are solving
Apply Principal component analysis to the data
preprocessing
compute pca with prcomp()
extract the first x PCs: broom::augment()
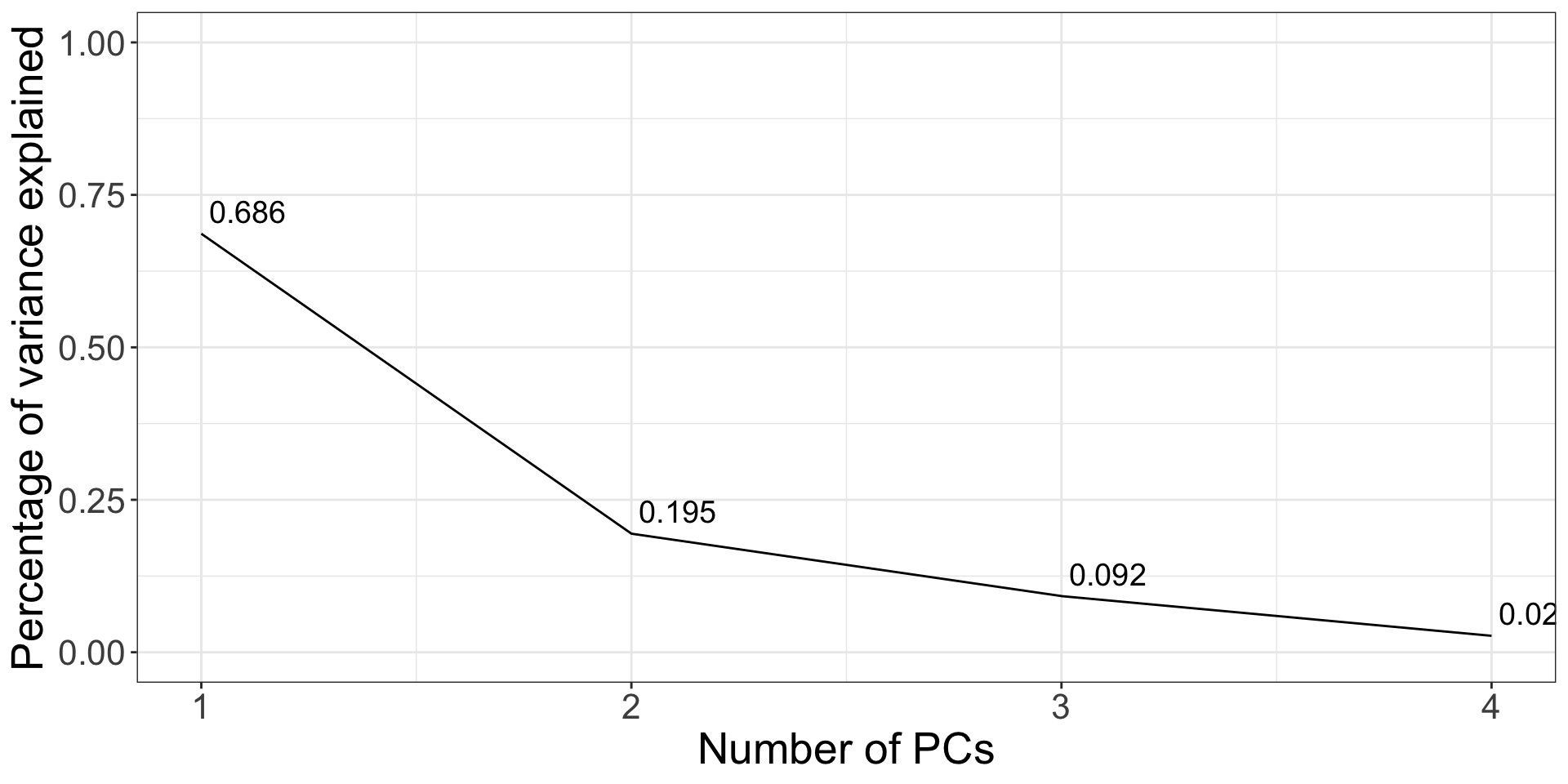
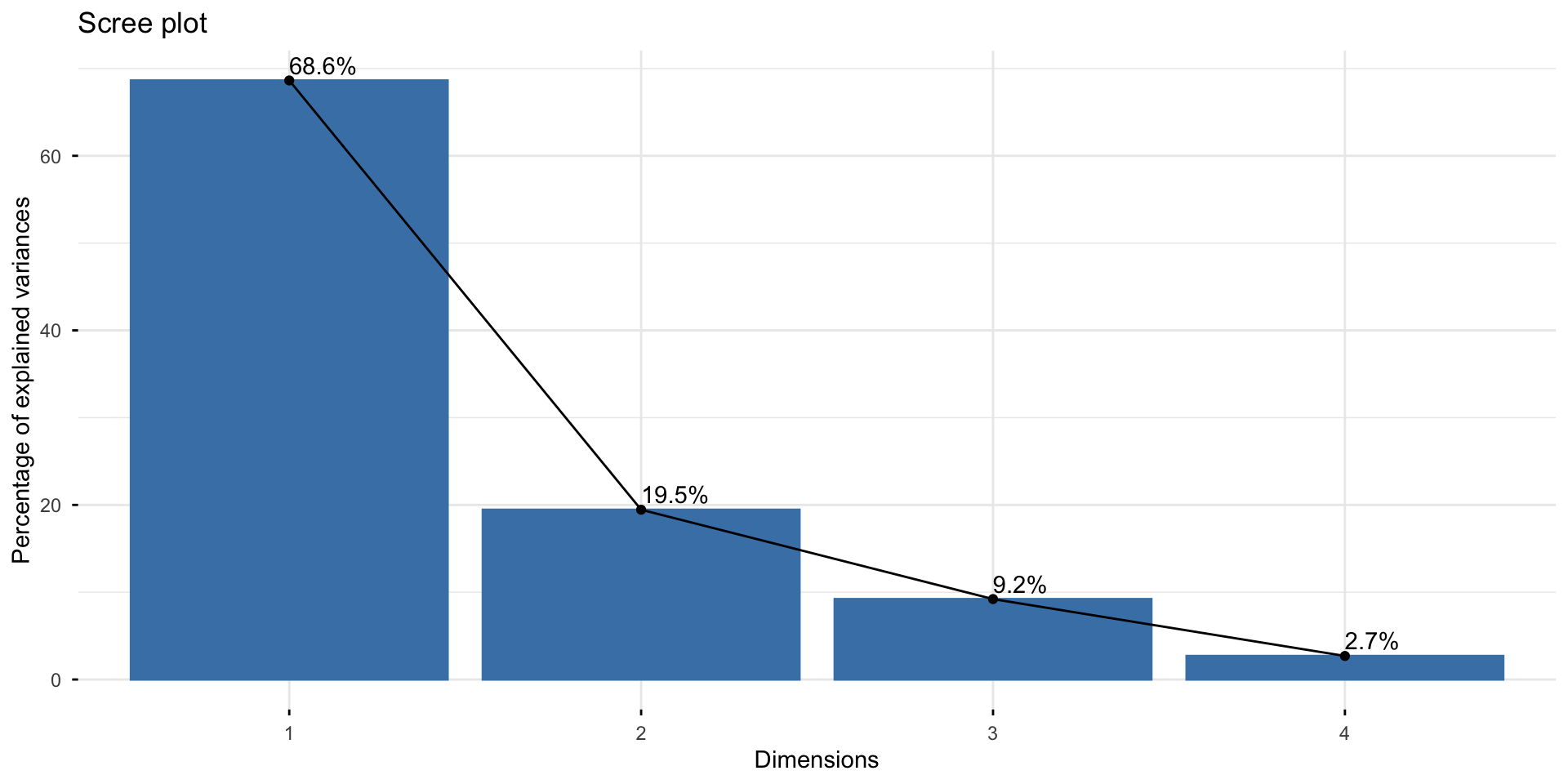
observe the screen plot to find the optimal number of PCs
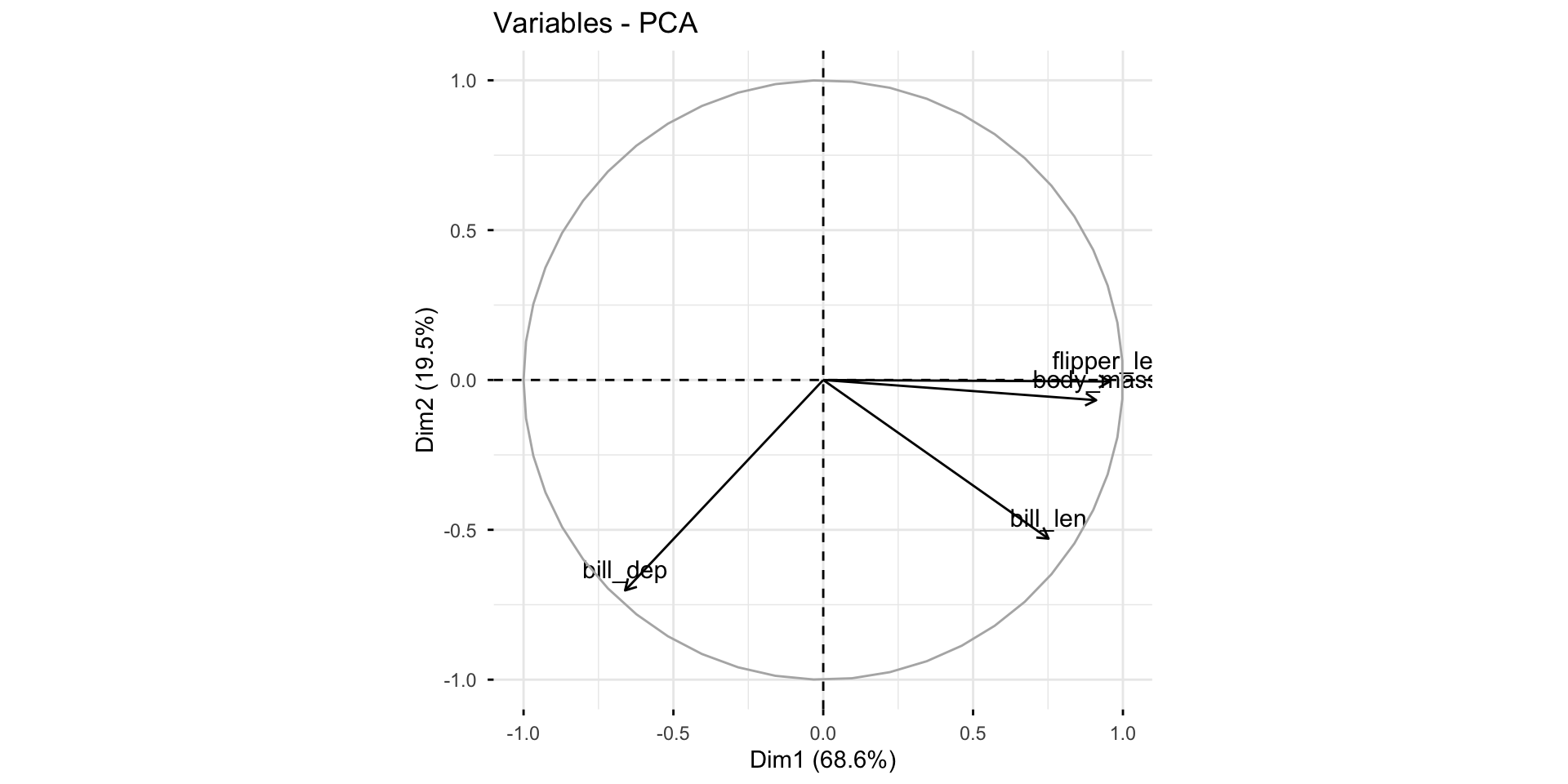
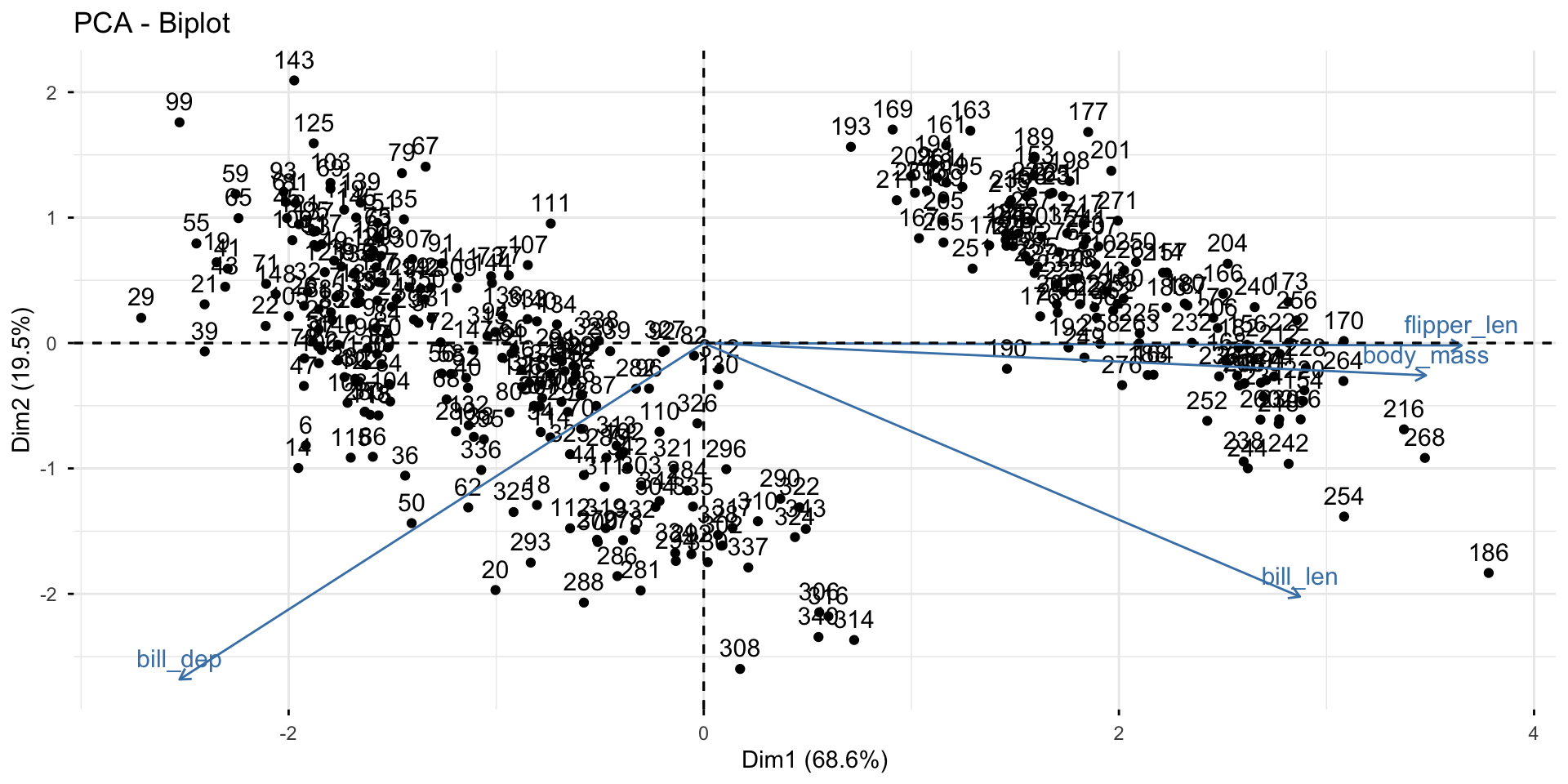
plot the data projected onto the first two PCs
Motivation - dimension reduction
Hand shadow puppet: 3D hand poses reduced to 2D shadows (Projection)
We want the projection to resemble the original data as much as possible.
Principal component analysis
Principal component analysis is a linear dimension reduction technique that finds a low-dimensional representation of a dataset that contains as much as possible of the variation.
It can be formulated as an optimization problem to maximize the variance of the projected data, subject to some constraint.
The solution to the optimization happens to be the singular value decomposition of the data matrix \(X\) (if the data has column mean of zero).
All of these will be taken care of by the function prcomp().
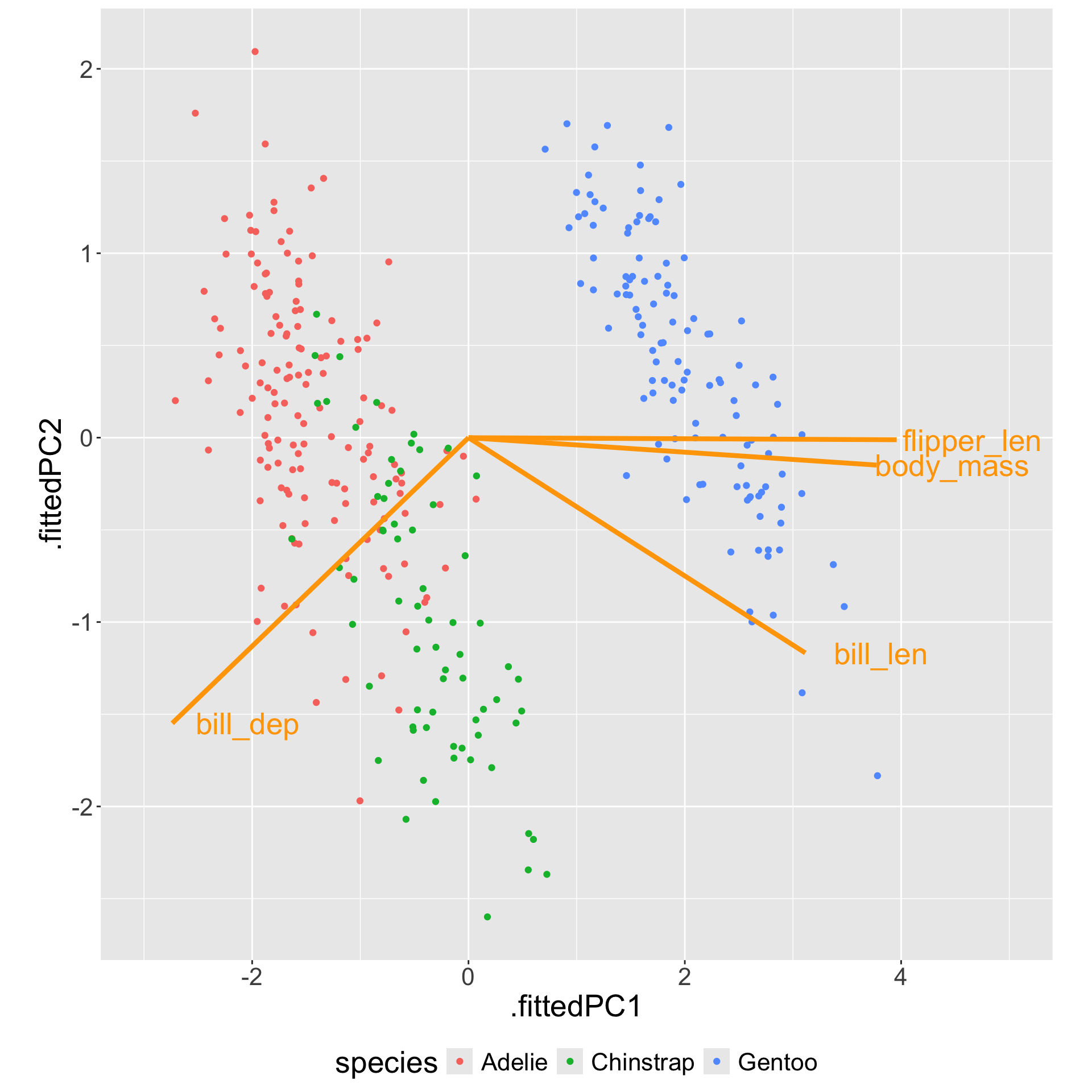
PCA example - Penguins data again
library(tidyverse)as_tibble(penguins)
# A tibble: 344 × 8
species island bill_len bill_dep flipper_len body_mass sex year
<fct> <fct> <dbl> <dbl> <int> <int> <fct> <int>
1 Adelie Torgersen 39.1 18.7 181 3750 male 2007
2 Adelie Torgersen 39.5 17.4 186 3800 female 2007
3 Adelie Torgersen 40.3 18 195 3250 female 2007
4 Adelie Torgersen NA NA NA NA <NA> 2007
5 Adelie Torgersen 36.7 19.3 193 3450 female 2007
# ℹ 339 more rows
Would you think missing values would be a problem for PCA?
Use Lagrange multipliers to solve the constrained optimization problem:
\[ L(\phi_1, \lambda) = \phi_1^T X^T X \phi_1 - \lambda (\phi_1^T \phi_1 - 1)\] Take the derivative and set it to zero gives \[X^TX\phi_1 = \lambda \phi_1\]
This is the eigenvalue equation for the matrix \(X^TX\).
Recognize \(X^TX\) is related the covariance matrix: \(S = \frac{1}{n-1}X^TX\), the first principal component (\(\phi_1\)) is the eigenvector of \(X^TX\) corresponding to the largest eigenvalue.
Computation
The first principal component (\(\phi_1\)) is the eigenvector of \(X^TX\) corresponding to the largest eigenvalue. This can be obtained through:
Singular value decomposition (SVD) of \(X\) (always apply):
\[X = UDV^T\]
Eigen-decomposition of \(X^TX = (n-1) S\) (since \(X^TX\) is square):
\[X^TX = V D^2 V^T\]
where
\(X\) is a \(n \times p\) matrix
\(U\) is a \(n \times n\) orthogonal matrix (\(U^TU = 1\))
\(D\) is a \(n \times p\) diagonal matrix with non-negative elements (square root of the eigenvalues of \(X^TX\) arranged in descending order)
\(V\) is a \(p \times p\) orthogonal matrix (eigenvectors: \(V^TV = 1\))
Principal component analysis
The second principal component (PC2): \(Z_2 = \phi_{12}X_1 + \phi_{22}X_2 + \dots + \phi_{p2}X_p\)
The second principal component is the linear combination of \(X_1, X_2, \dots, X_p\) that has the largest variance out of all linear combinations that are uncorrelated with \(Z_1\).
subject to “\(Z_2\) being uncorrelated with \(Z_1\)”.
This is equivalent to constraining \(\phi_2\) to be orthogonal to \(\phi_1\), hence
\[\max_{\phi_{12}, \dots, \phi_{p2}} \text{Var}(Z_2) = \max_{\phi_{12}, \dots, \phi_{p2}} \frac{1}{n}\sum_{i = 1}^n (\sum_{j = 1}^p \phi_{j2} x_{ij})^2 \] subject to the normalization constraint \(\sum _{i=1}^{p} \phi_{i2}^2 = 1\) and the orthogonality constraint \(\sum_{i=1}^{p} \phi_{i1}\phi_{i2} = 0\).