Interpretation: Keeping all other variables constant, a 1 gram increase in body mass is on average associated with an increase of 0.00278201 in the log-odds of being male.
Exercise: How would you interpret the coefficient for flipper length?
Keeping all other variables constant, a 1mm increase in flipper length is on average associated with a decrease of 0.09325684 in the log-odds of being male.
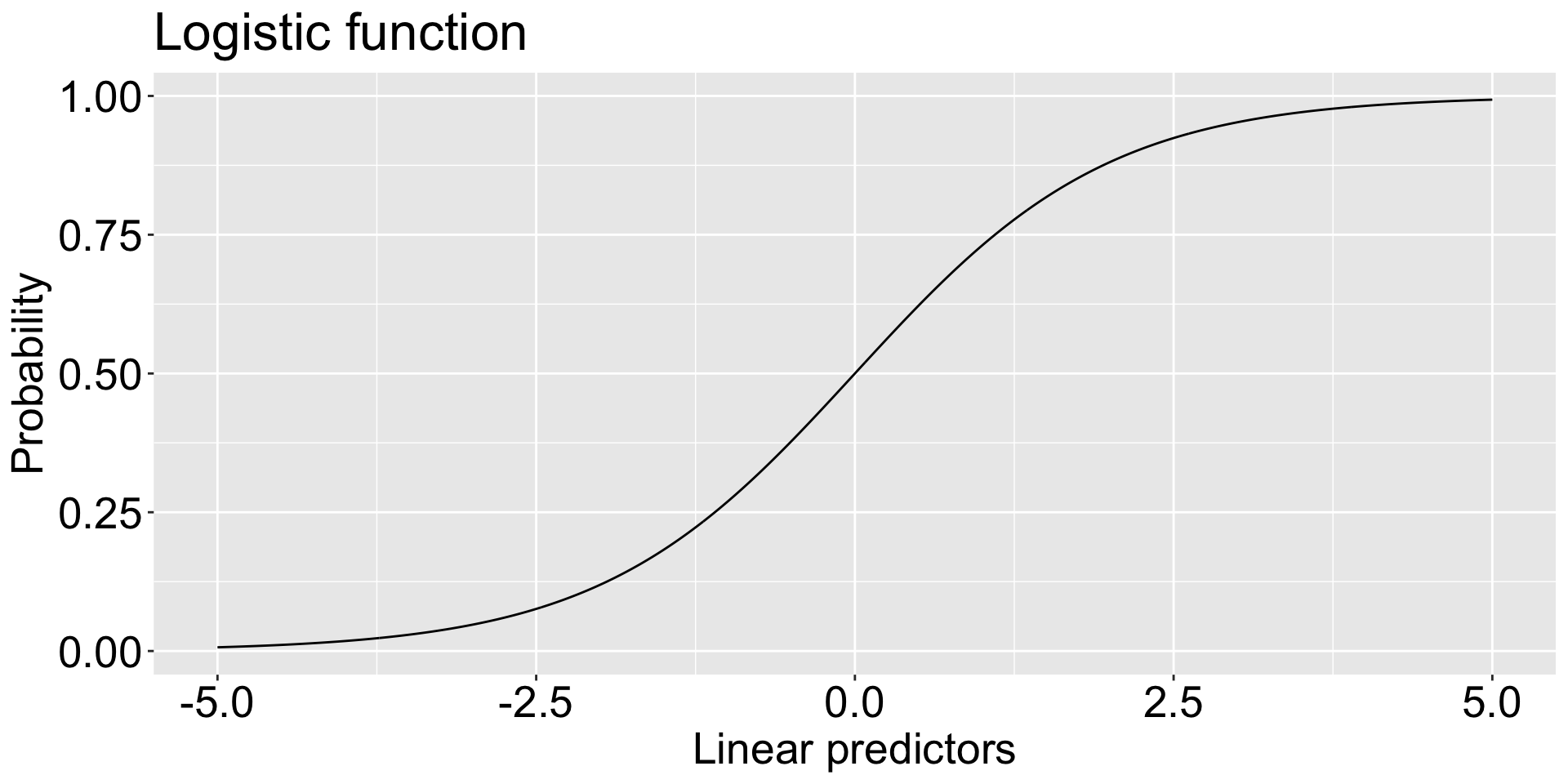
type = "link" gives the prediction of the linear predictors: (-Inf, Inf)
pred_link <-predict(mod1, type ="link") head(pred_link, 4)
1 2 3 4
0.6398517 0.3126680 -2.0567488 -1.3138332
type = "response" gives the prediction of the odds/ probability: [0, 1]
pred_response <-predict(mod1, type ="response")head(pred_response, 4)
1 2 3 4
0.6547199 0.5775364 0.1133722 0.2118461
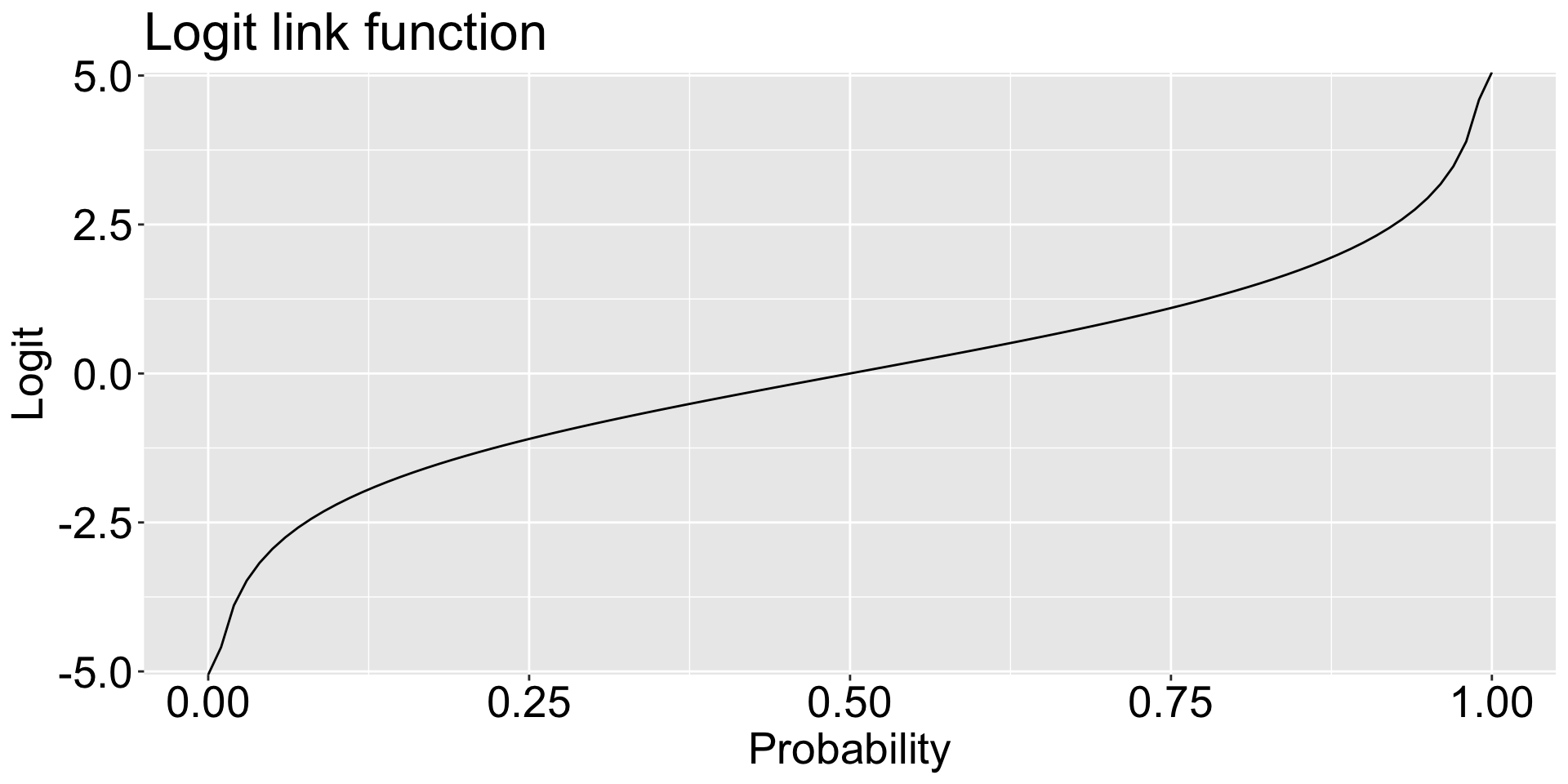
If we take the prediction in probability and convert it with the log-odds function, \(\log \frac{p}{1-p}\), we get the prediction in linear predictors:
log(pred_response[1:4] /(1- pred_response[1:4]))
1 2 3 4
0.6398517 0.3126680 -2.0567488 -1.3138332
Example: Predictions from logistic models
How should we decide where to cut off the predicted probabilities to classify sex?
A reasonable choice is 0.5: if predicted probability > 0.5, classify as male (1); otherwise female (0)
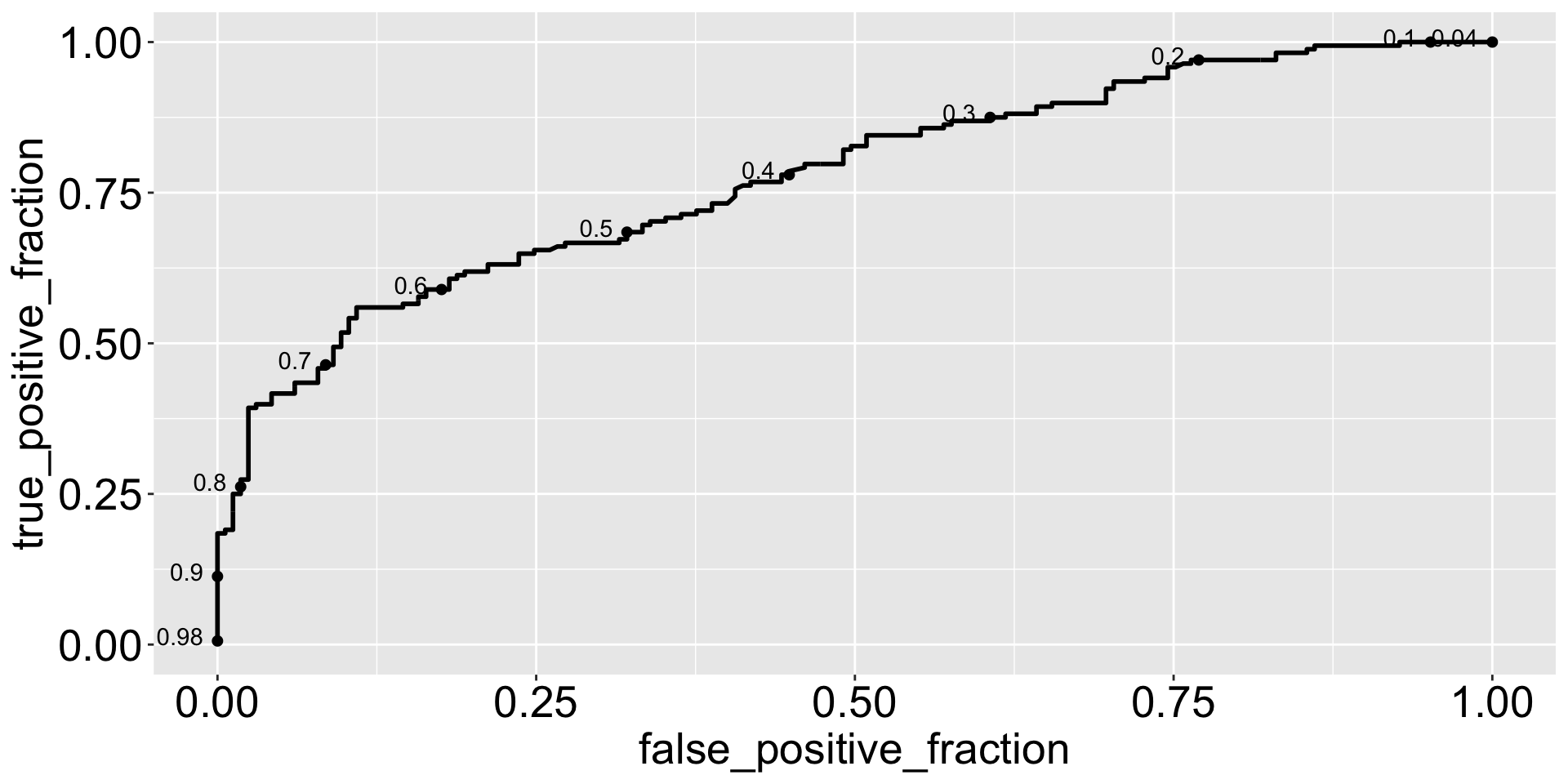
penguins_clean |>mutate(pred =predict(mod1, type ="response")) |>ggplot() +geom_roc(aes(m = pred, d = sex), cutoffs.at =seq(0,1, 0.1), labelround =2)
m refers to the continous Measurement and d refers to the binary Diagnosis (not necessarily the best naming).
The ROC curve shows the trade-off between true positive rate and false positive rate at different threshold values.
Is this a good model?
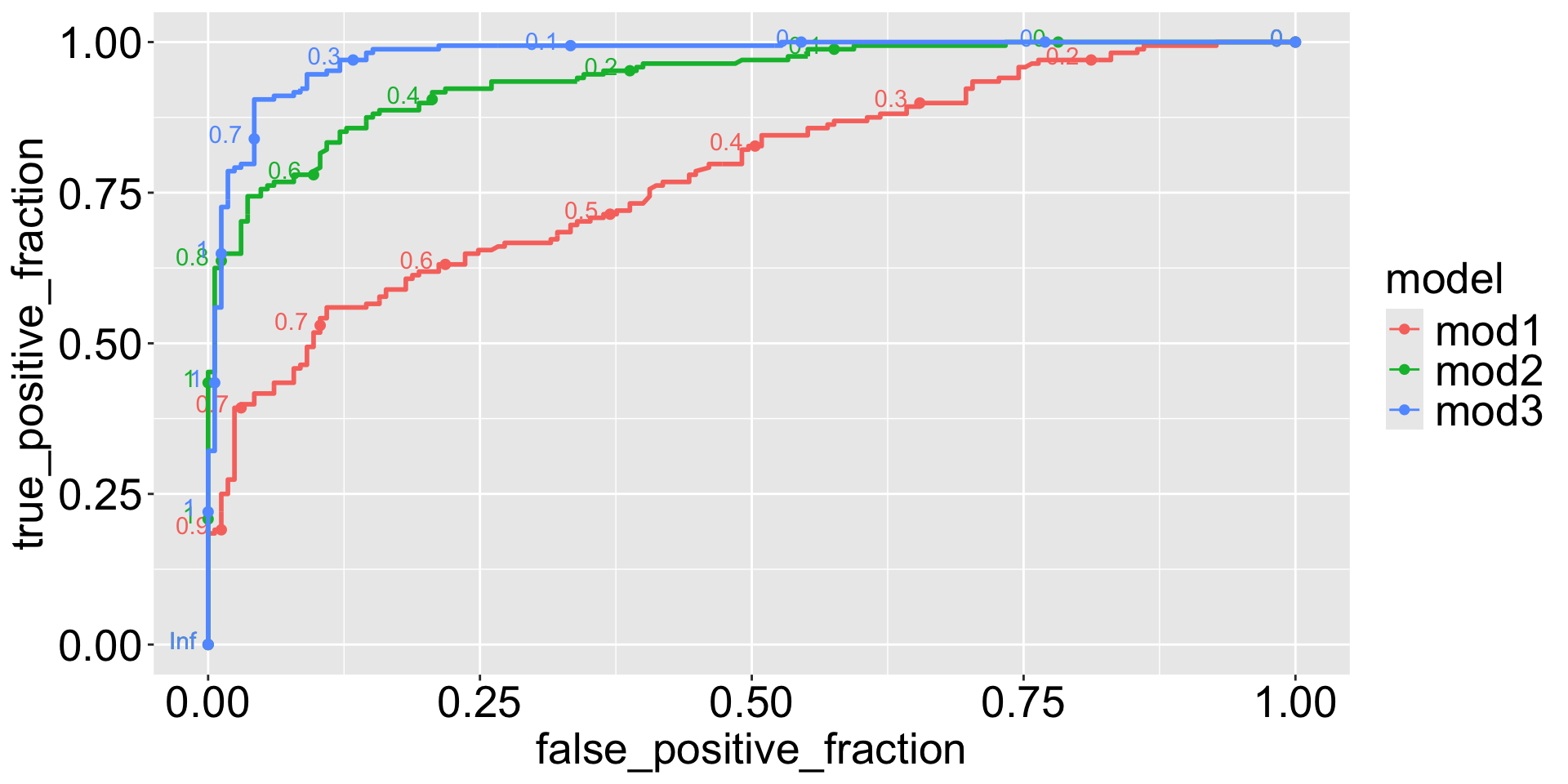
Example: Model comparison
mod2 <-glm(sex ~ body_mass + flipper_len + species, family = binomial,data = penguins_clean)mod3 <-glm(sex ~ body_mass + flipper_len + bill_len + bill_dep + species, family = binomial, data = penguins_clean)
Model 3 is the best among the three.
Example: Model comparison
summary(mod3)
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 461.61 on 332 degrees of freedom
Residual deviance: 127.11 on 326 degrees of freedom
AIC: 141.11
Number of Fisher Scoring iterations: 7
The summary seems to be different from linear models (mod0):
summary(mod0)
Residual standard error: 0.4387 on 330 degrees of freedom
Multiple R-squared: 0.237, Adjusted R-squared: 0.2324
F-statistic: 51.26 on 2 and 330 DF, p-value: < 2.2e-16
Why we care about deviance in logistic?
Example: Model comparison
Deviance measures how well the model fits the data. Lower, better.
Null deviance represents the deviance of a model with only an intercept (no predictors).
Residual deviance represents the deviance of the fitted model with predictors.
We can compare models using deviance: a significant reduction in deviance when adding predictors indicates that the predictors improve the model fit.