# A tibble: 5 × 3
female male class
<dbl> <dbl> <chr>
1 0.2 0.8 male
2 1 0 female
3 0.4 0.6 male
4 0.6 0.4 female
5 0.2 0.8 male
table(pred_knn_df$class, penguins_std$sex)
female male
female 146 18
male 19 150
How do we compare the accuracy of KNN and logistic regression?
This time, we are comparing two different machine learning algorithms, rather than different specifications of the same model, like we did with linear model.
A little script to compare KNN and logistic regression on synthetic data
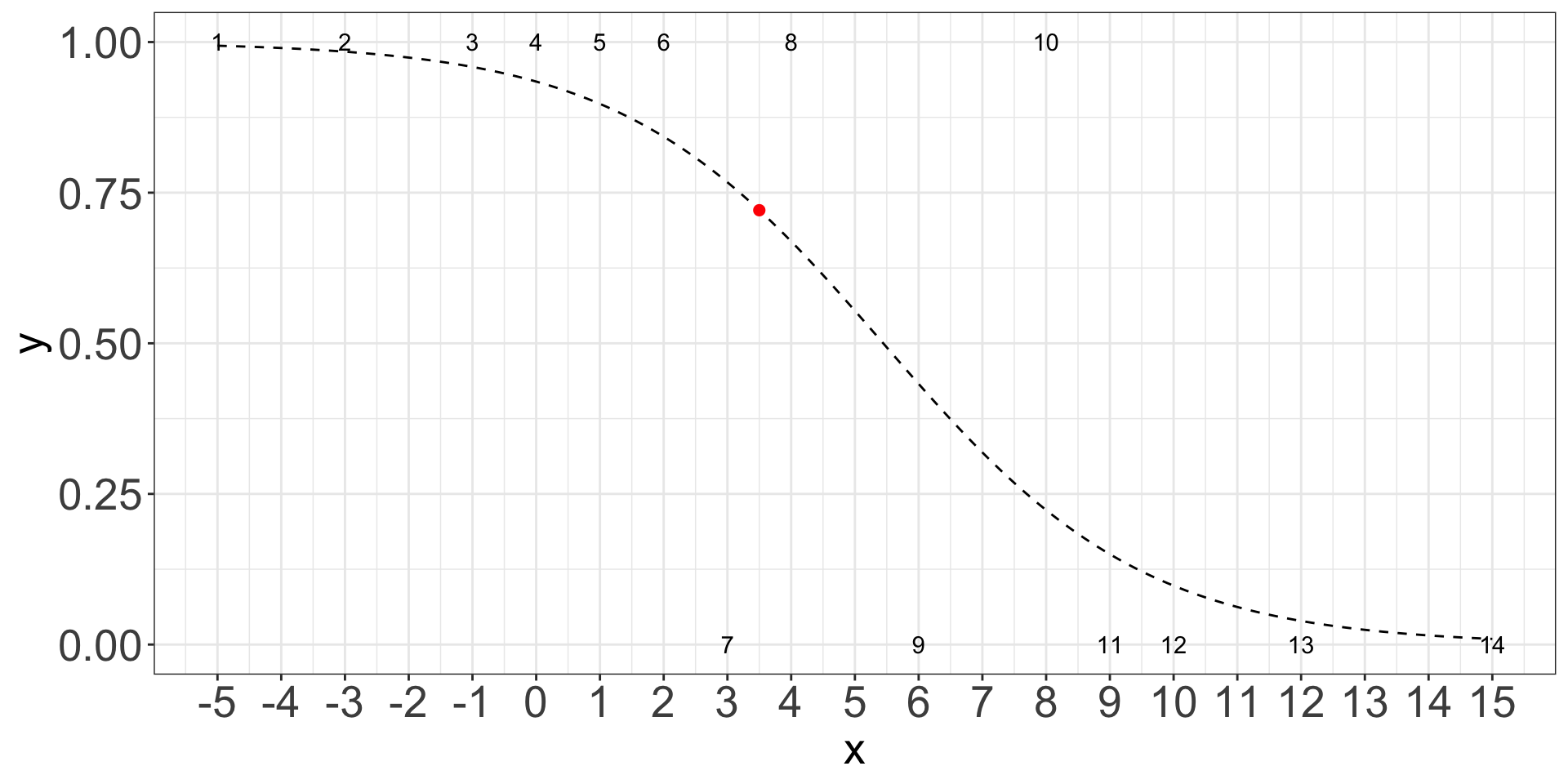
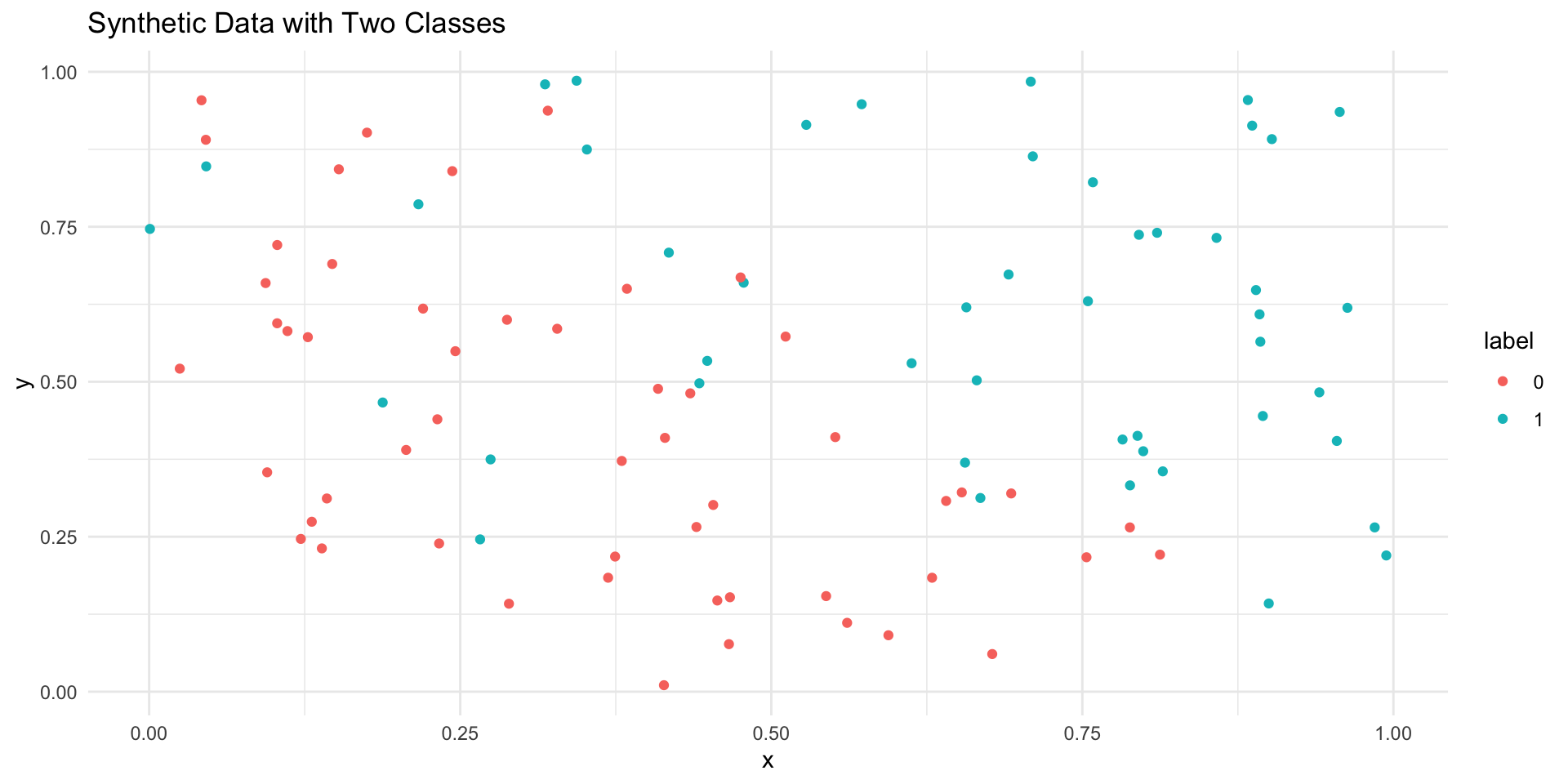
set.seed(123)n <-100x <-runif(n, 0, 1)y <-runif(n, 0, 1)label <-ifelse(x + y +rnorm(n, 0, 0.3) >1, 1, 0) # add noisedata <-data.frame(x, y, label)logit_model <-glm(label ~ x + y, data = data, family = binomial)logit_pred <-ifelse(predict(logit_model, type ="response") >0.5, 1, 0)logic_acc <-mean(logit_pred == data$label)knn_model <-knn3(label ~ x + y, data = data, k =7)knn_pred <-as_tibble(predict(knn_model, newdata = data)) |>mutate(class =ifelse(`0`>`1`, 0, 1)) |>pull(class)knn_acc <-mean(knn_pred == data$label)tibble(x = x, y = y, label =factor(label)) %>%ggplot(aes(x = x, y = y, color = label)) +geom_point() +labs(title ="Synthetic Data with Two Classes") +theme_minimal()
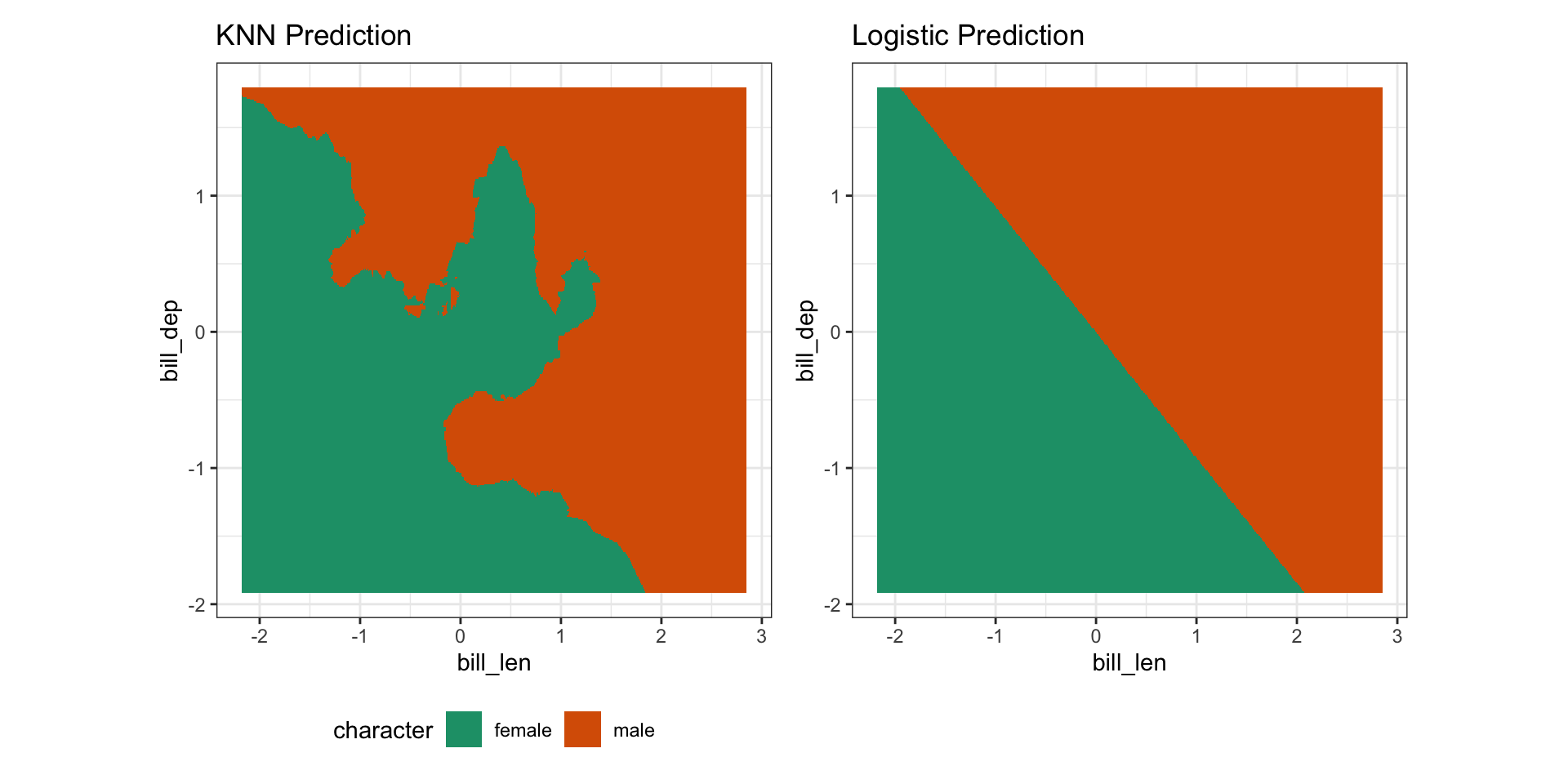
Repeat the procedure we had before and fit the KNN model and compare the prediction, specifically
Step 1: conduct the same training testing split
Step 2: fit the KNN model with the new sex2 as the response
Step 3: compute the prediction and compare with the original result
Solution
# Step 1: conduct the same training testing splitpenguins_std <- penguins_clean2 |>select(bill_len, bill_dep) |>scale() |>bind_cols(sex2 = penguins_clean2$sex2)m <-nrow(penguins_std)set.seed(123)val <-sample(1:m, size =round(m/3), replace =FALSE)penguins_training2 <- penguins_std[-val,]penguins_testing2 <- penguins_std[val,]# Step 2: fit the KNN model with the new `sex2` as the responseknn_res2 <-knn3(sex2 ~ bill_len + bill_dep, data = penguins_training2)# Step 3: compute the prediction and compare with the original resultas_tibble(predict(knn_res2, newdata = penguins_testing2)) |>mutate(pred_class =ifelse(`0`>0.5, 0, 1),other_class = pred_knn_df$class) |>count(pred_class, other_class)
# A tibble: 2 × 3
pred_class other_class n
<dbl> <chr> <int>
1 0 female 58
2 1 male 53
Now we can see they are the same!
What would be the best k?
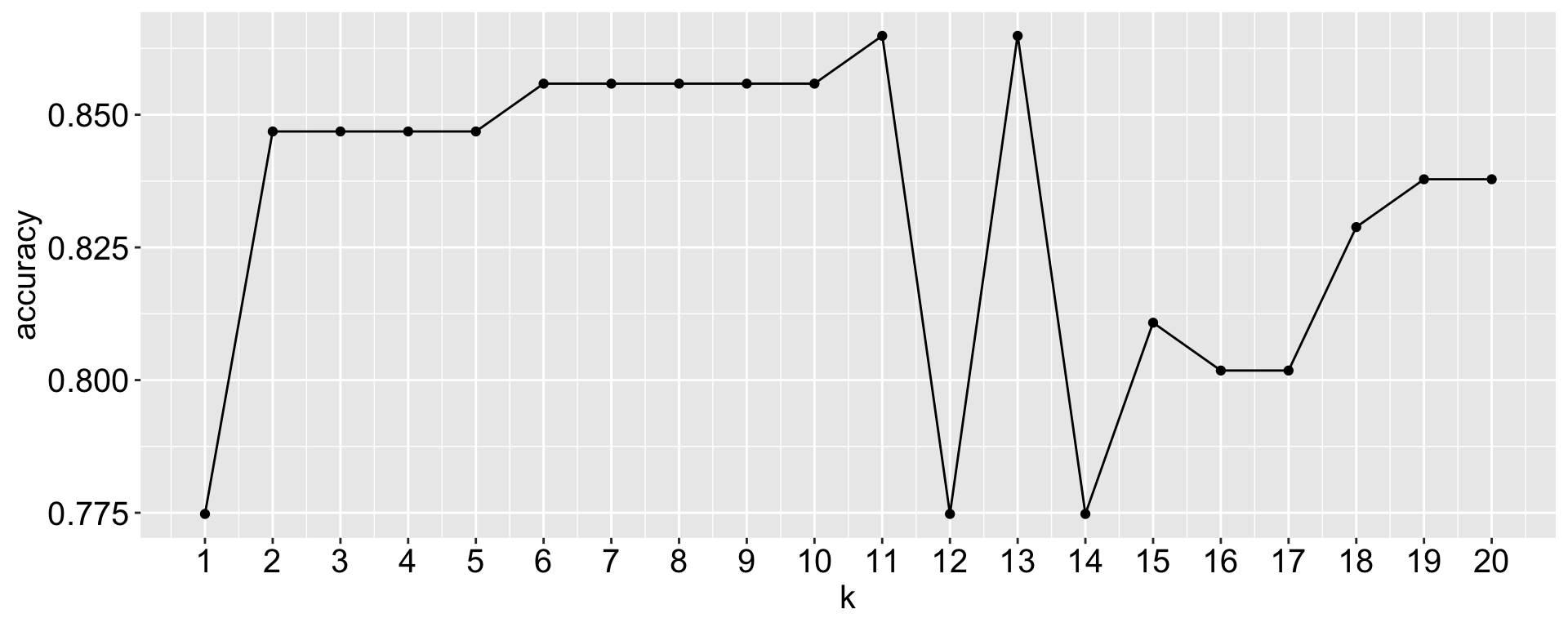
A naive try: for what we have done, run the kknn() for different k values and see which one gives the best accuracy on the testing set.
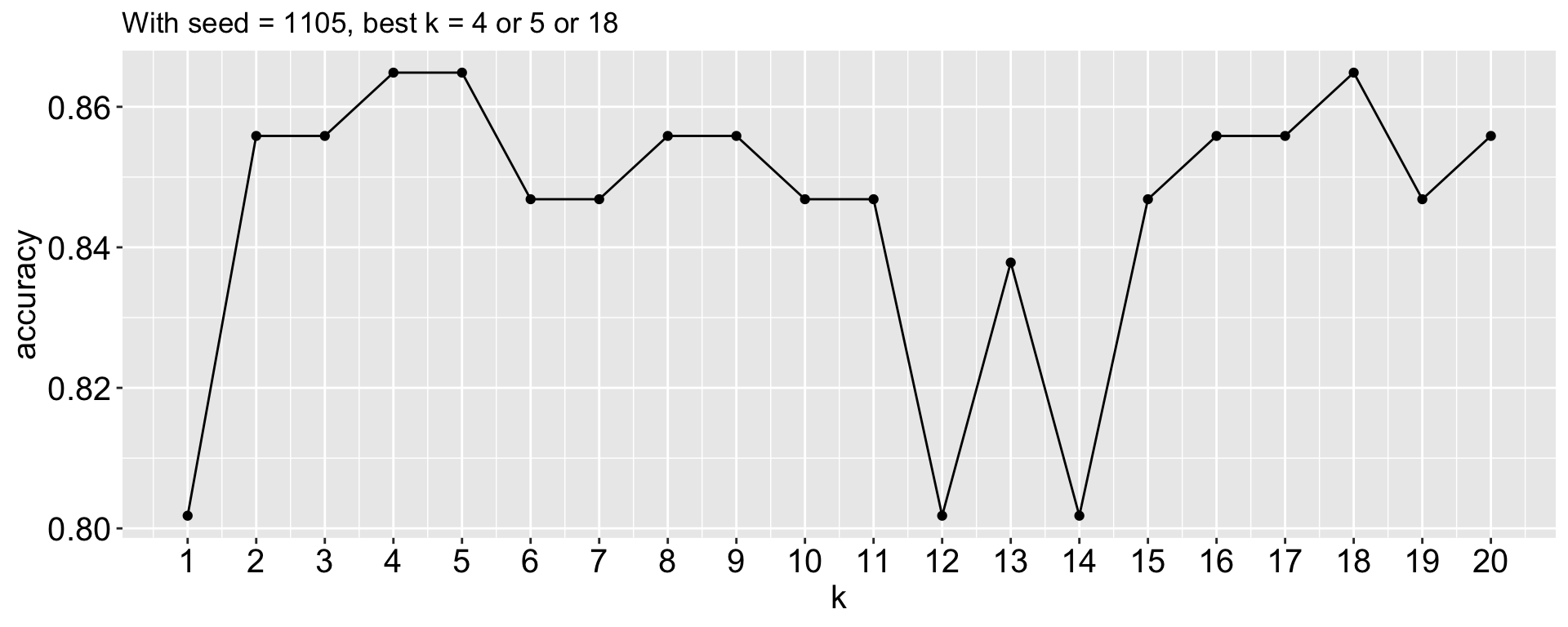
Here I compute the proportion of accurate prediction for each k from 1 to 20. Which k would you choose?
Does that mean k = 11/ 13 is the best k?
What would be the best k?
Not necessarily! Because the training-testing split is random, different splits may lead to different best k values.
seed: 123, best k = 11 or 13
seed: 12345, best k = 4 or 5 or 18
seed: 1105, best k = 13
A little script to play around with
# Step 1: conduct the same training testing splitpenguins_std <- penguins_clean |>select(bill_len, bill_dep) |>scale() |>bind_cols(sex = penguins_clean2$sex)m <-nrow(penguins_std)set.seed(12345)val <-sample(1:m, size =round(m/3), replace =FALSE)penguins_training2 <- penguins_std[-val,]penguins_testing2 <- penguins_std[val,]# Step 2: fit the KNN model with different k_vec# you can think of this as for each k, we make a prediction of the 111 testing points# this gives us 20 * 111 = 2220 predictionsk_vec <-1:20k_res <-map_dfr(k_vec, function(k){ knn_res2 <-kknn(sex ~ bill_len + bill_dep, k = k,train = penguins_training2, test = penguins_testing2) res <-tibble(pred_class =predict(knn_res2))tibble(pred = res$pred_class, sex = penguins_testing2$sex)}, .id ="k")# Step 3: compute the prediction accuracy for each k and plot itacc_count_df <- k_res |>group_split(k) |>map_dfr(~count(.x, pred, sex), .id ="k") |>filter(pred == sex) |>mutate(k =as.integer(k)) |>group_by(k) |>summarize(accuracy =sum(n) /111) acc_count_df |>ggplot(aes(x = k, y = accuracy)) +geom_line() +geom_point() +scale_x_continuous(breaks =1:20) +ggtitle("With seed = 1105, best k = 4 or 5 or 18")
We have lot of variability in the best k depending on the training-testing split.
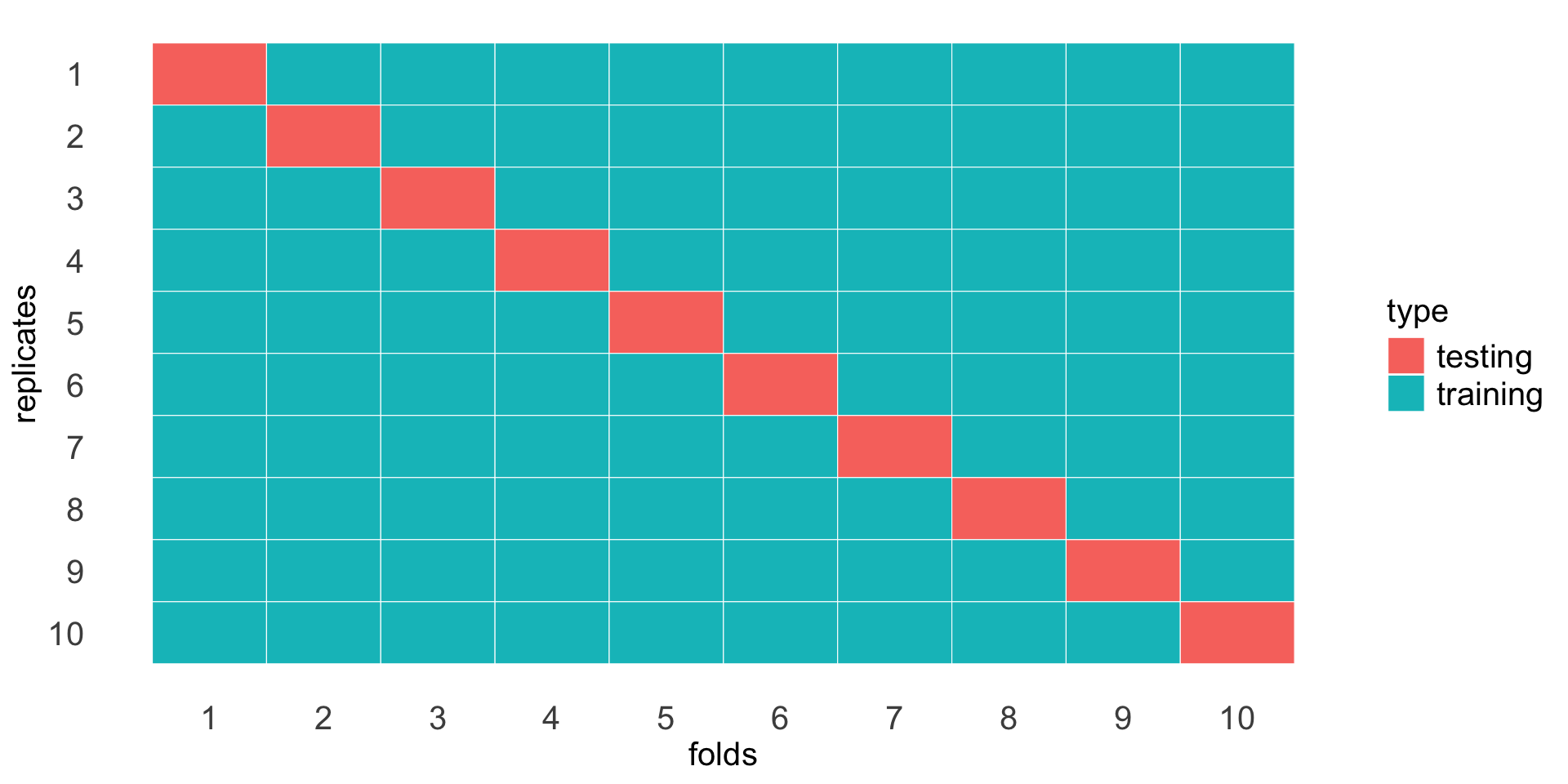
Cross validation
To reduce the variance, we would like some average performance across different training-testing splits - This is the idea behind cross validation.
We can split the data into 10 folds (or any number of folds), and use 9 folds as training and 1 fold as testing, repeat this for each fold as testing, and average the accuracy across the 10 folds for each k.
A not so little script to do cross validation for KNN
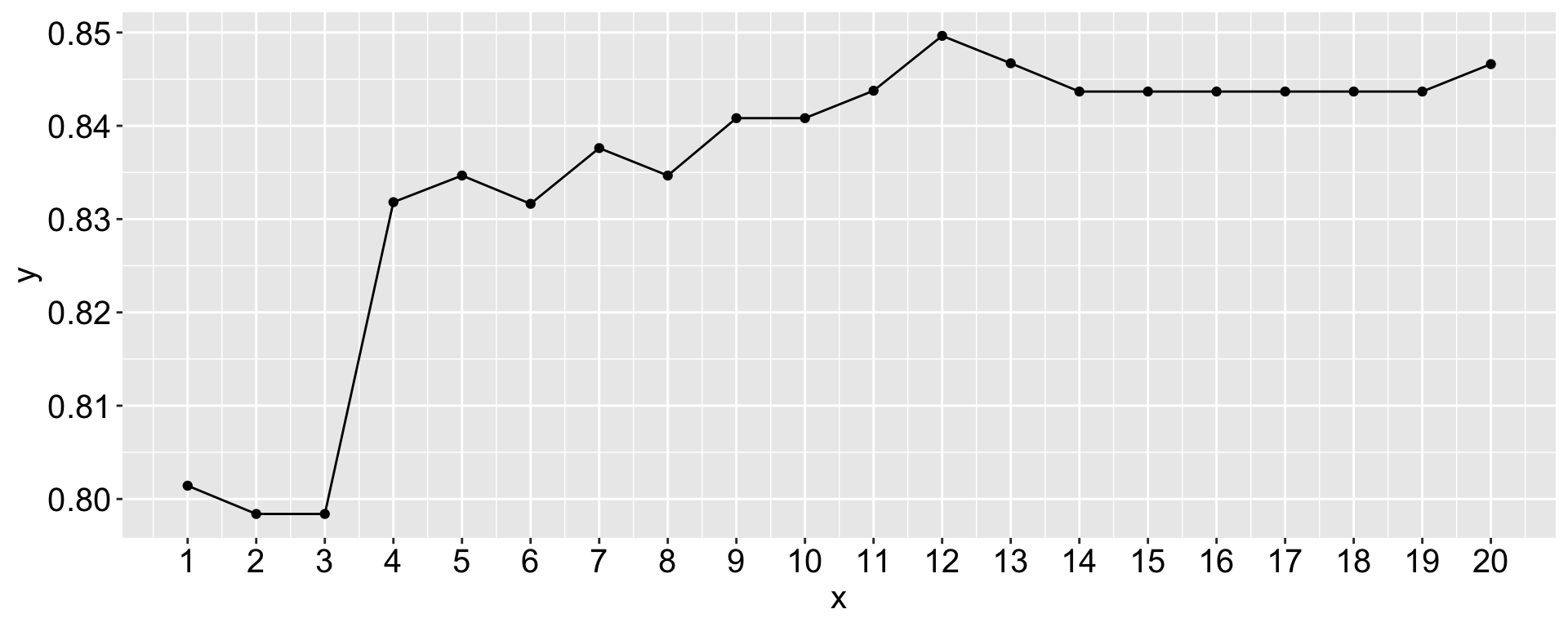
library(kknn)library(caret)set.seed(123)penguins_clean <-as_tibble(datasets::penguins) |>na.omit() penguins_std <- penguins_clean |>select(bill_len, bill_dep) |>scale() |>bind_cols(sex = penguins_clean$sex)folds <-createFolds(penguins_std$sex, k =10)k_values <-1:20acc_k <-numeric(length(k_values))for (j inseq_along(k_values)) { acc_fold <-c()for (i in1:10) { test_idx <- folds[[i]] train_data <- penguins_std[-test_idx, ] test_data <- penguins_std[test_idx, ] mod <-kknn(sex ~ bill_len + bill_dep,train = train_data,test = test_data,k = k_values[j]) pred <-fitted(mod) acc_fold[i] <-mean(pred == test_data$sex) } acc_k[j] <-mean(acc_fold)}# Show best kbest_k <- k_values[which.max(acc_k)]tibble(x =1:20, y = acc_k) |>ggplot(aes(x = x, y = y)) +geom_point() +geom_line() +scale_x_continuous(breaks =1:20)
You’re not required to write this code! We will learn how to specify it with tidymodels in the next class.