A few things that are inconvenient with a data frame:
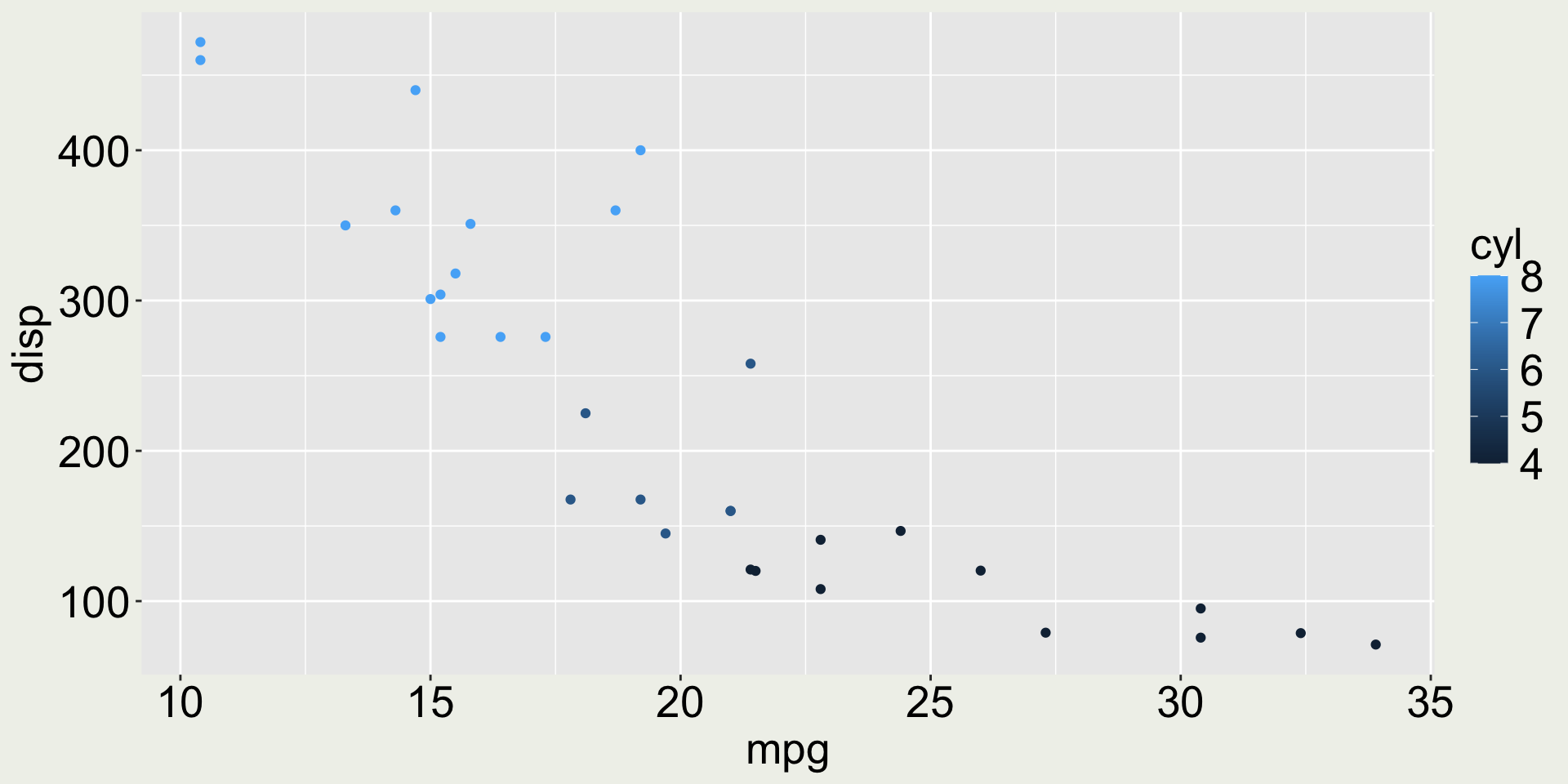
A data frame will print all the rows, while a tibble only prints the first 10 rows. You will need to scroll all the way up to see the column names in a data frame.
A tibble has a few prints that make it easier to know your data, e.g. 1) data dimension: 32 x 11, 2) variable type: <dbl>
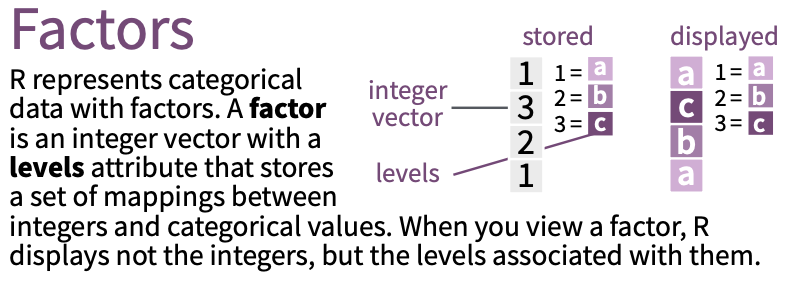
Convert a data frame to a tibble
For some historical reasons, a data frame allows you to specify a rowname:
They are perceptually uniform: meaning that values close to each other have similar-appearing colors and values far away from each other have more different-appearing colors, consistently across the range of values.
They are robust to colorblindness, so that the above properties hold true for people with common forms of colorblindness, as well as in grey scale printing.
What about the rainbow palette?
The rainbow palette is not uniformly perceived.
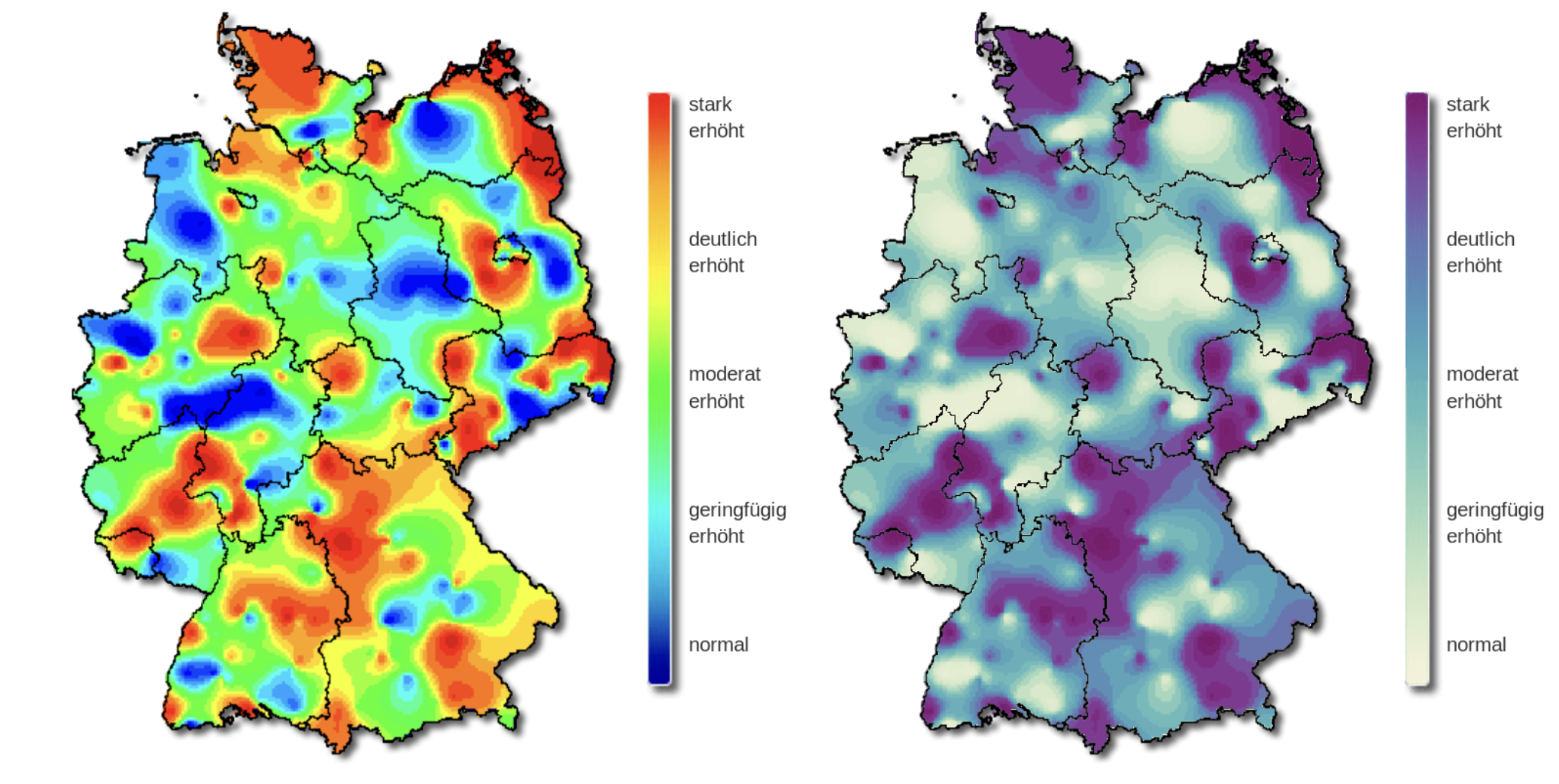
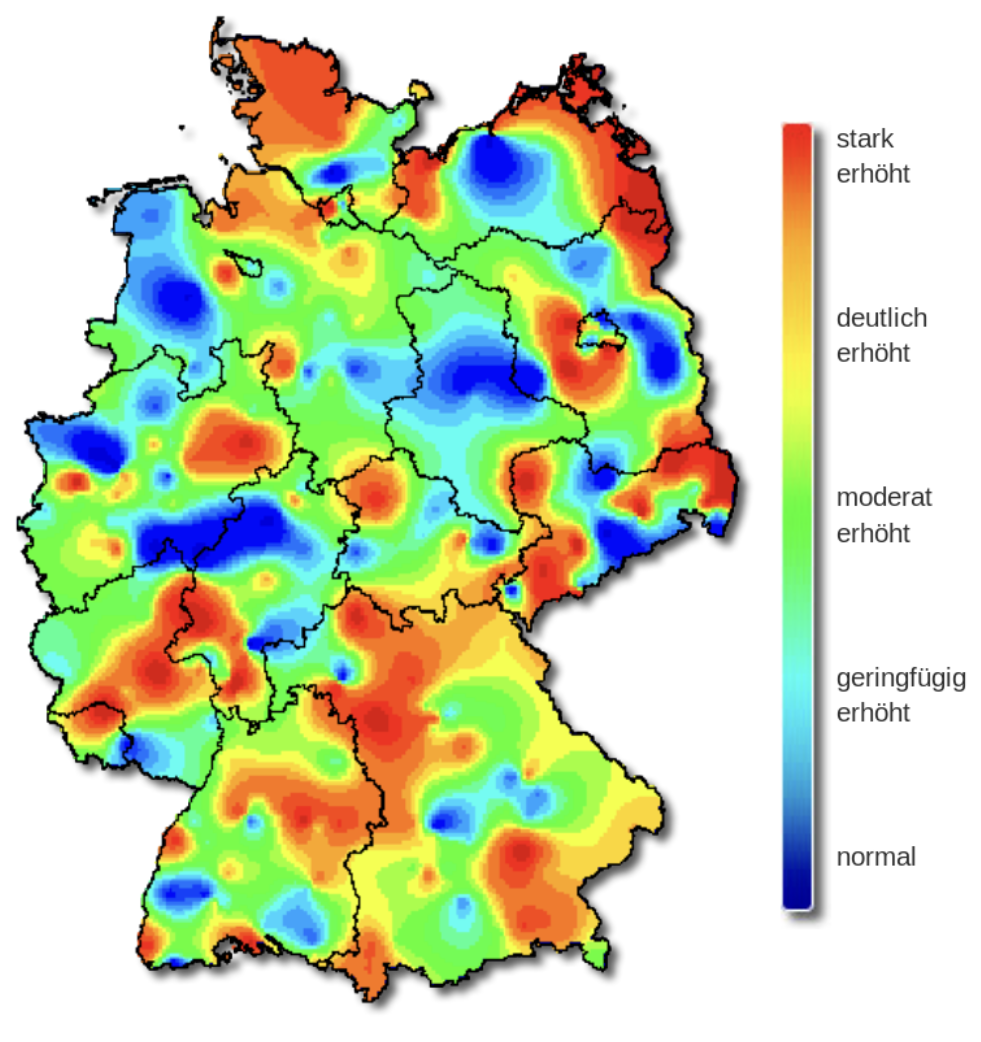
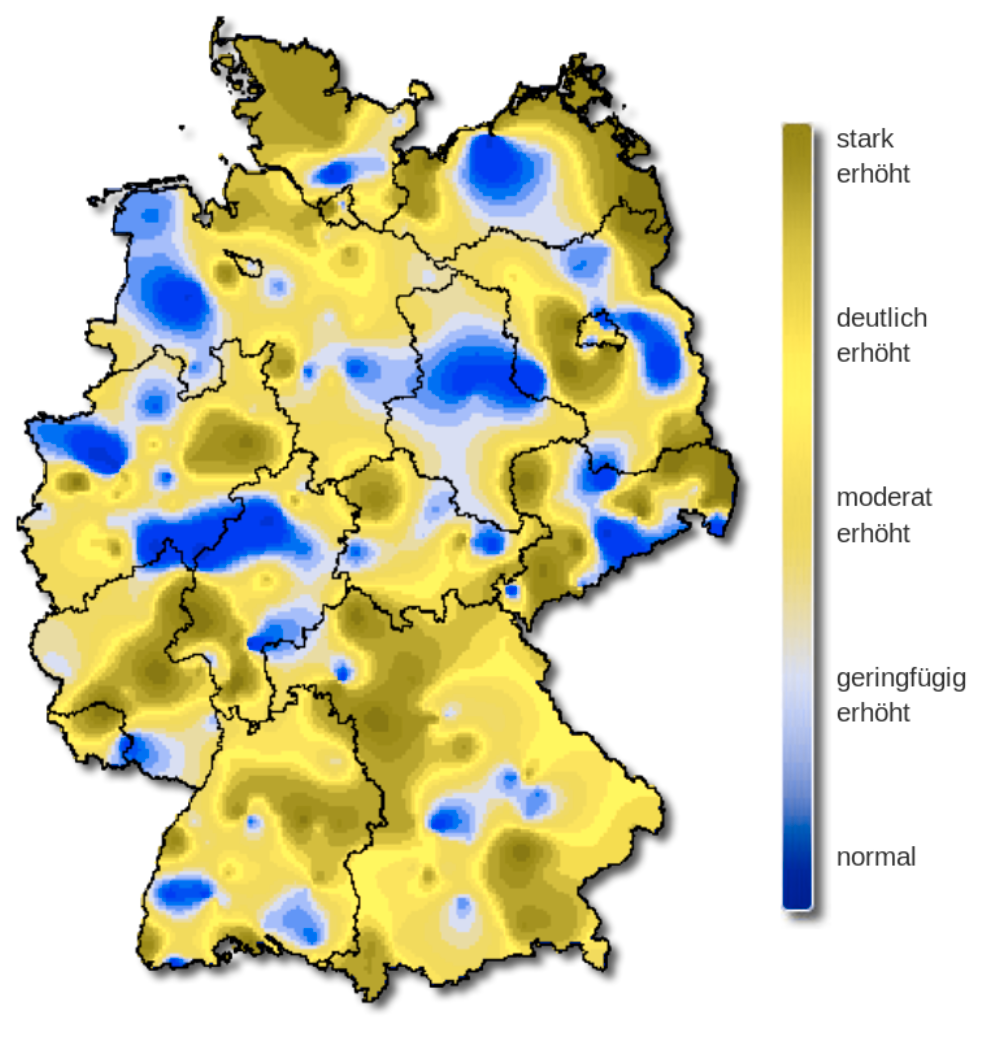
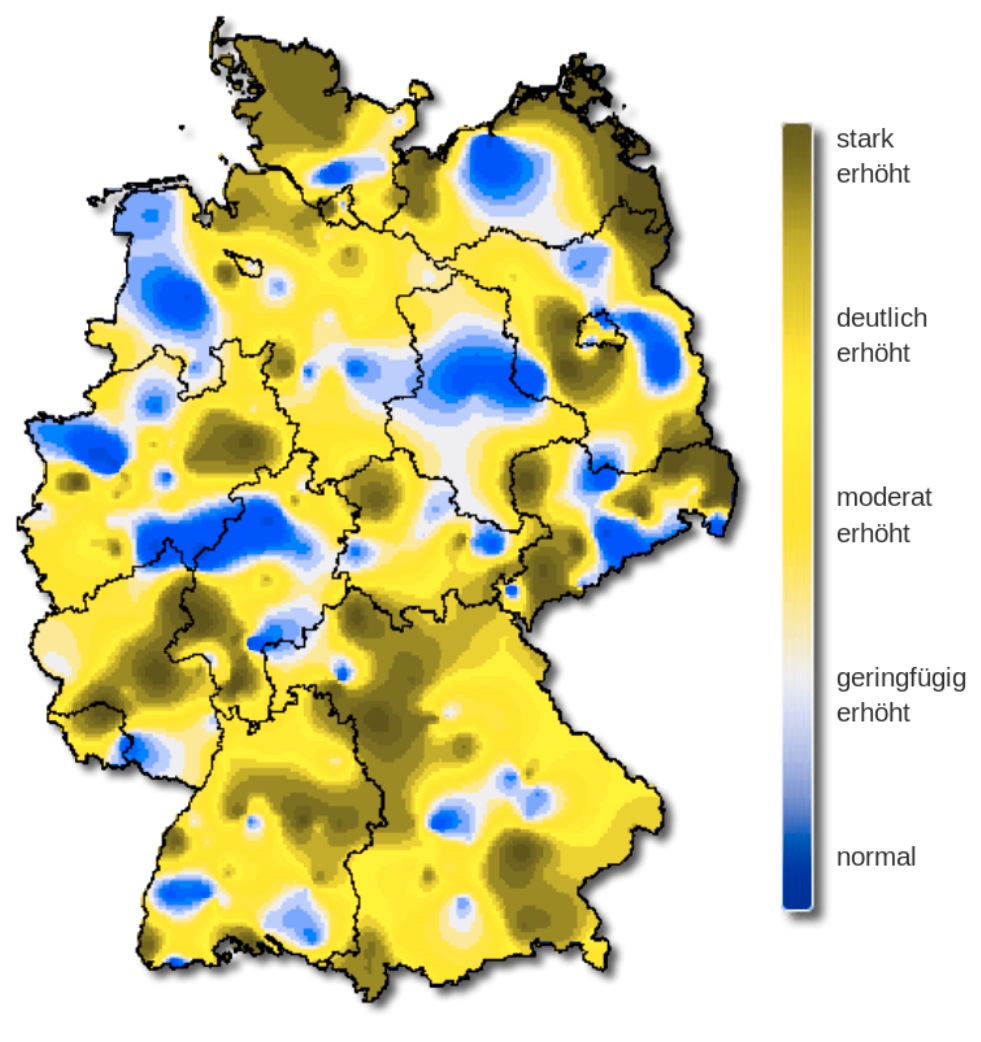
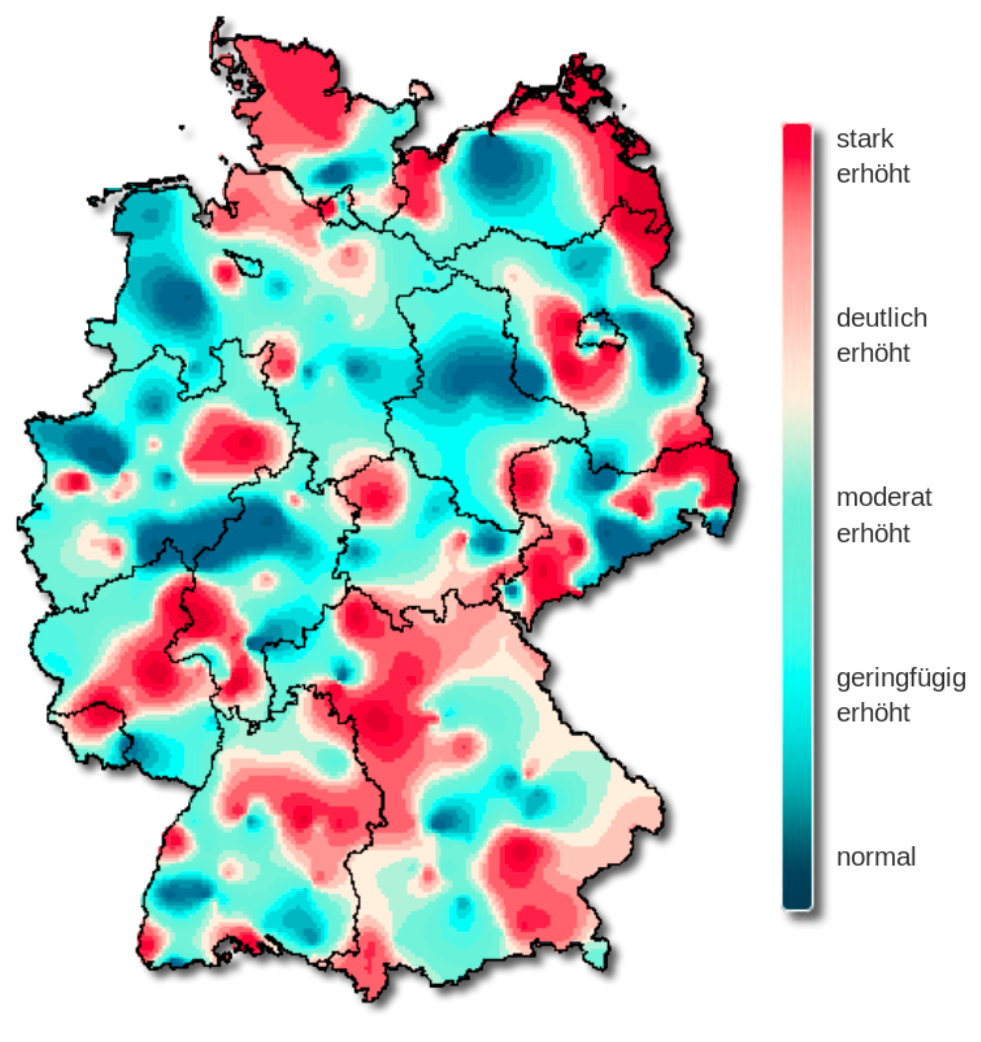
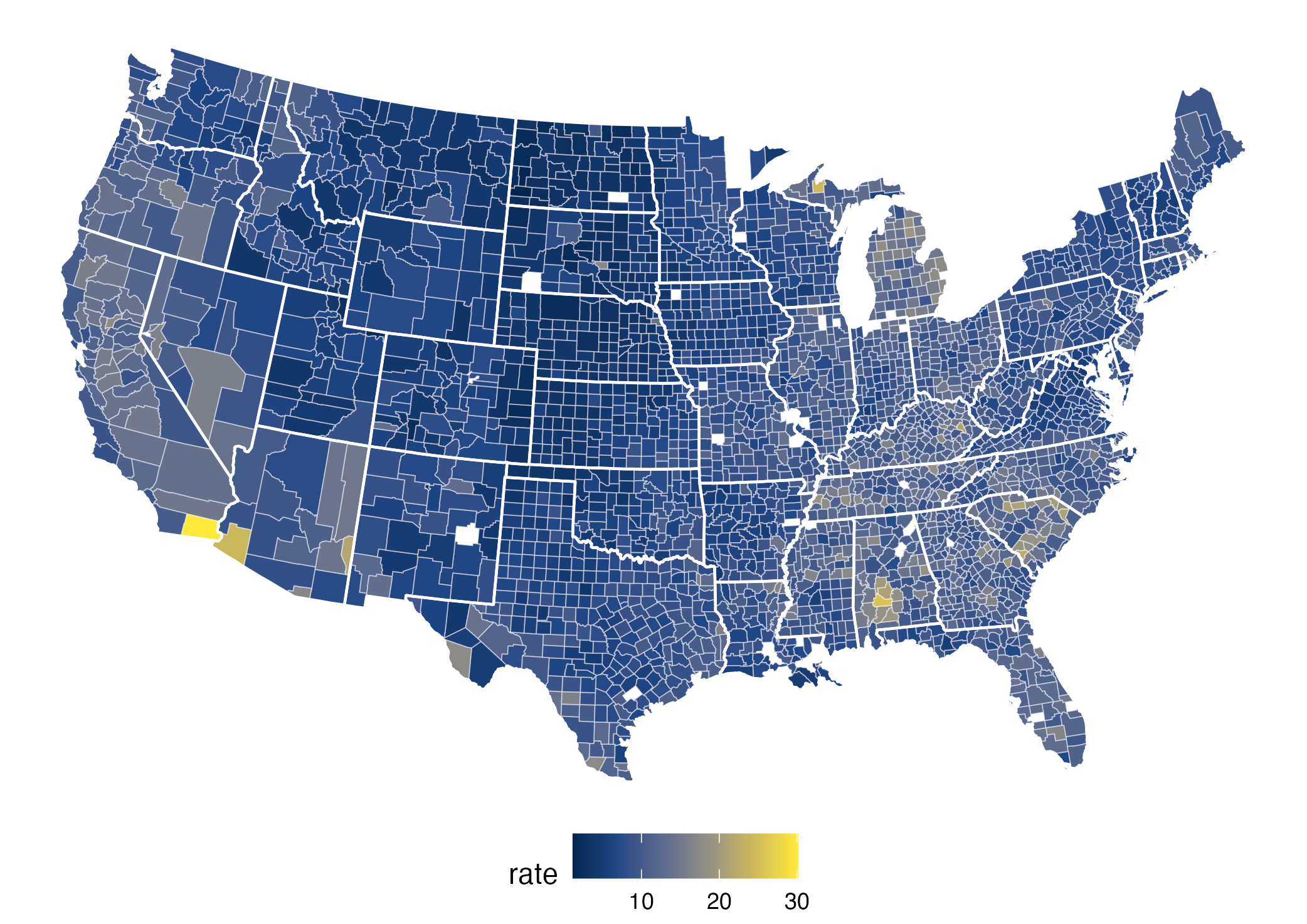
The severity of influenza in Germany in week 8, 2019.
The original color palette (left) is the classic rainbow ranging from “normal” (blue) to “strongly increased” (red).
Color blindness
normal
tritanopia: reduced sensitivity to blue light (extremely rare)
protanopia: reduced sensitivity to red light
deuteranopia: reduced sensitivity to green light (most common)
What does that mean to a color palette?
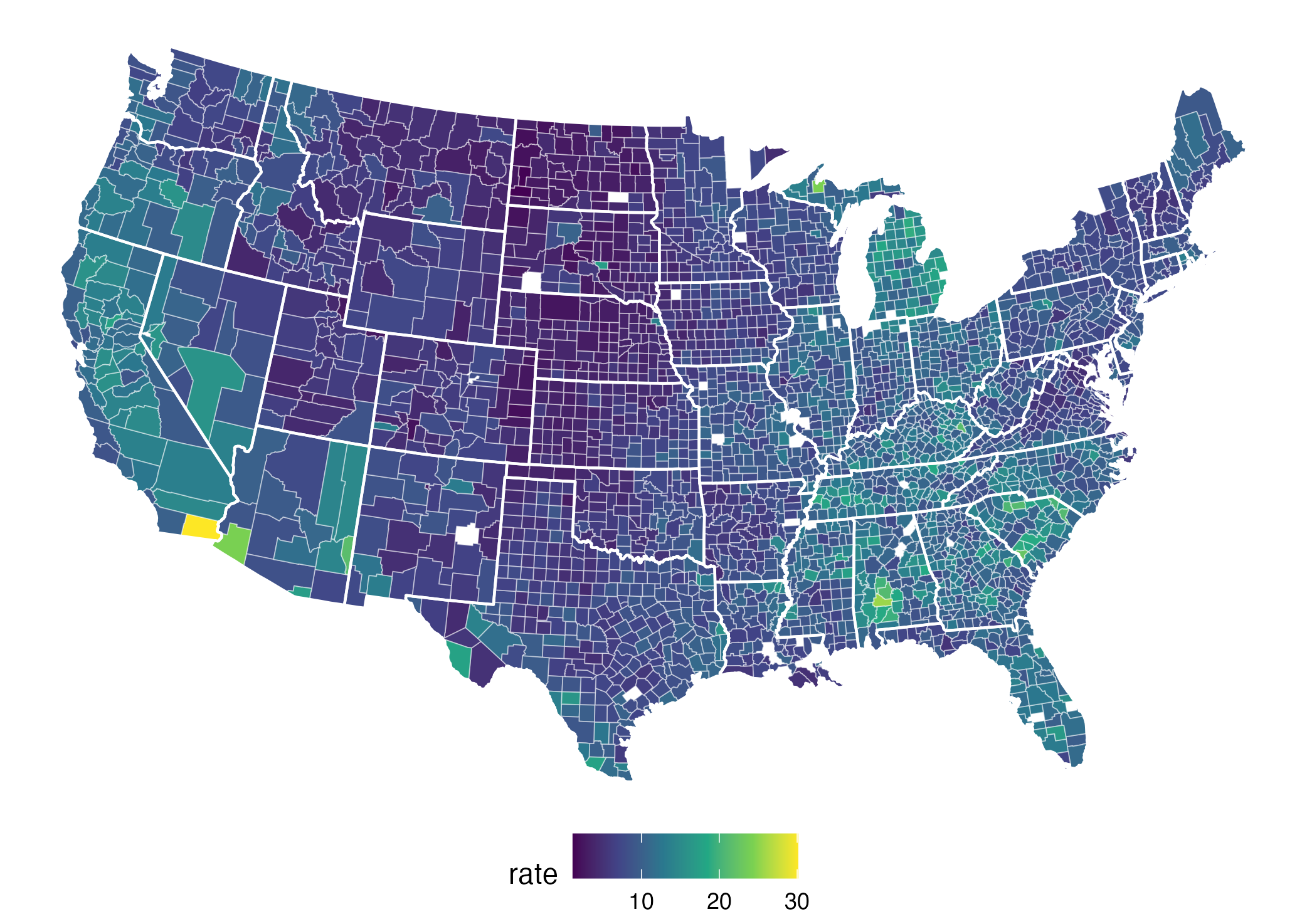
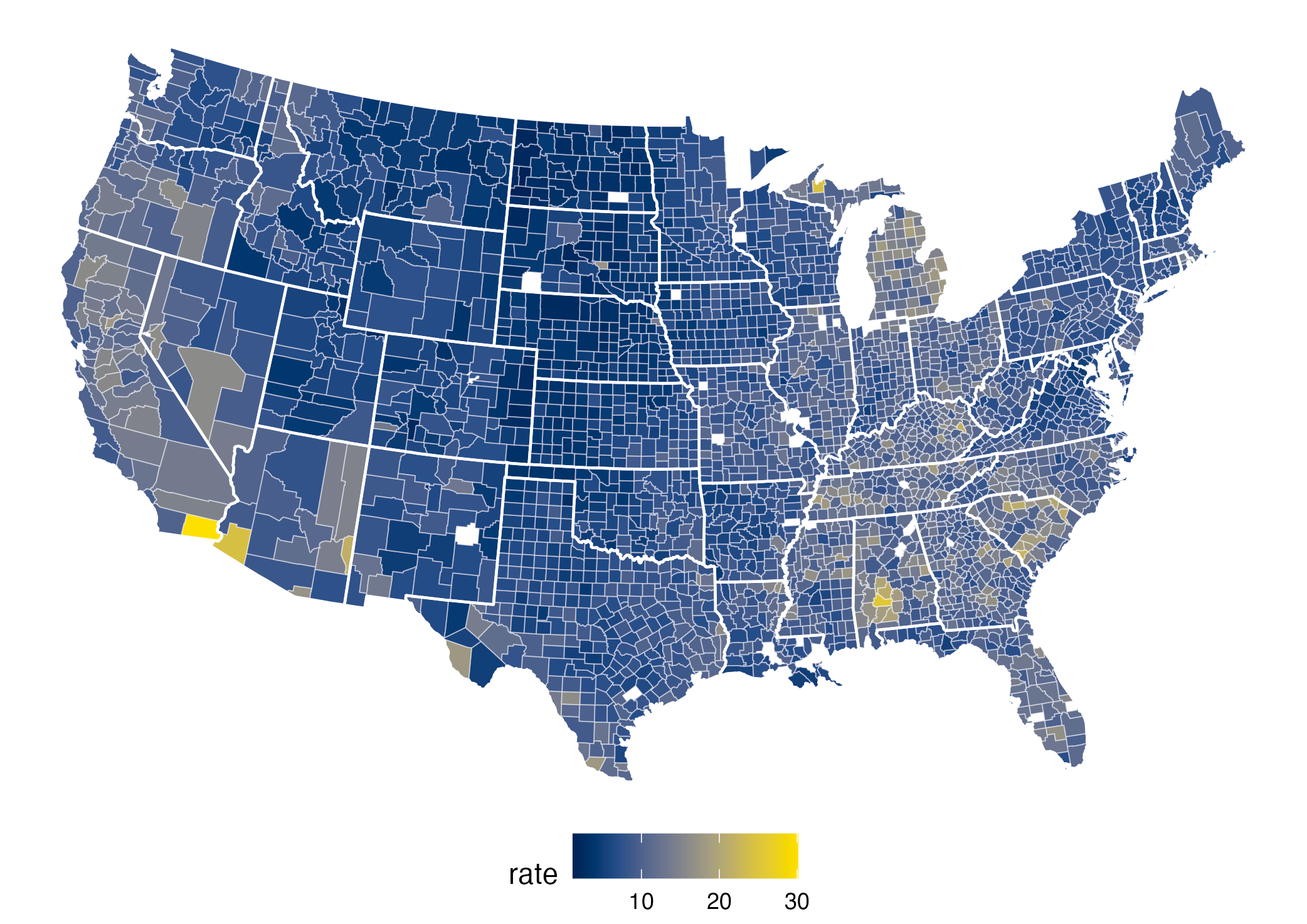
The rainbow palette
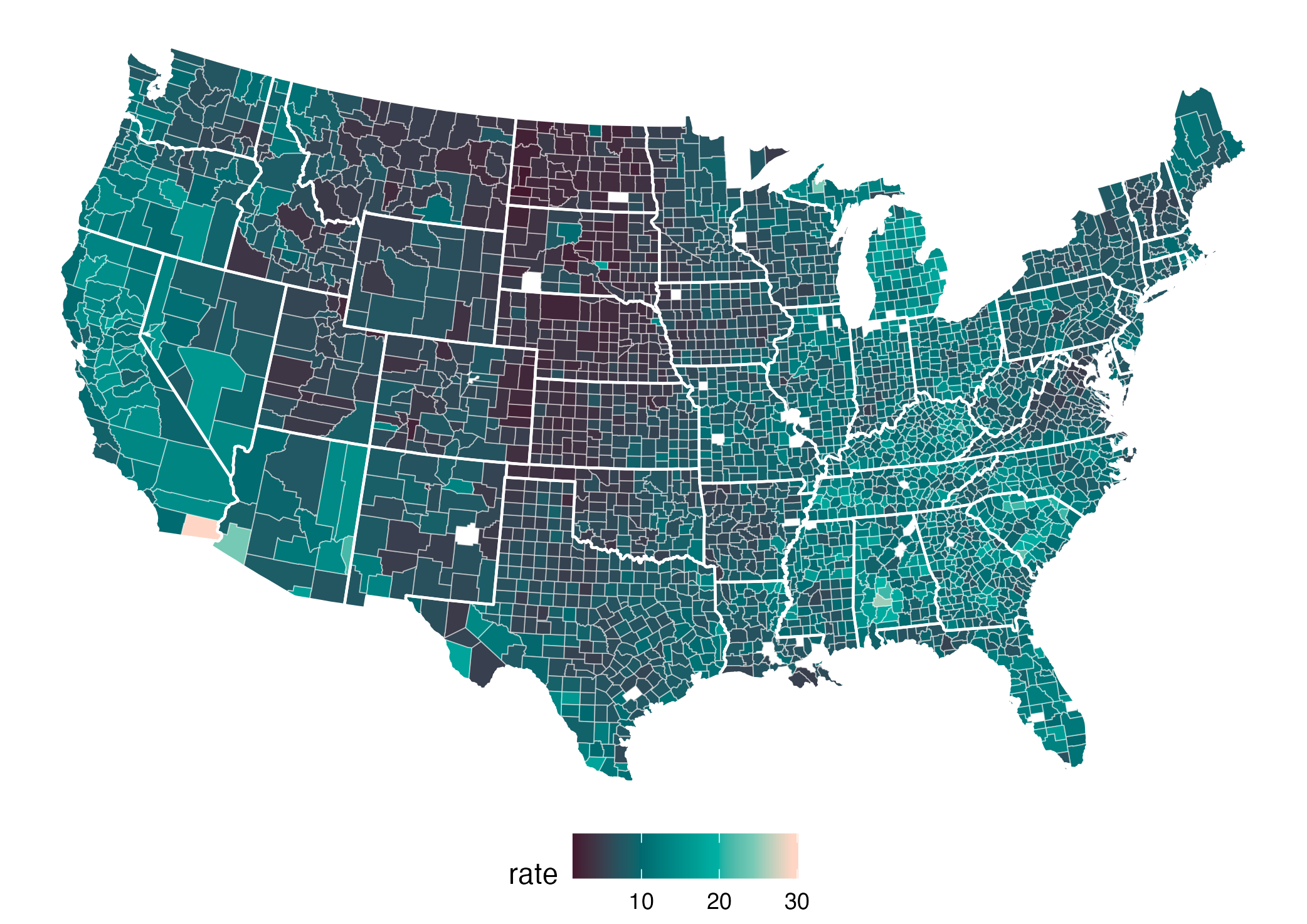
The viridis palette
Color blindness affects about 8% of all males and 0.5% of all females!
What does that mean on the plot?
Normal
Deuteranopia
Protanopia
Tritanopia
The rainbow color palette is also not color blind-friendly because baseline color (blue) gets emphasized with deuteranopia and protanopia.
What does that mean on the plot?
normal
tritanopia
protanopia
deuteranopia (most common)
Good color platettes go beyond viridis
Three types of color schemes designed for different types of data:
Qualitative: for categorical information, i.e., where no particular ordering of categories is available and every color should receive the same perceptual weight.
Sequential: for ordered/numeric information, i.e., going from high to low (or vice versa).
Diverging: for ordered/numeric information around a central neutral value, i.e., where colors diverge from neutral to two extremes.
To use ggthemes, you need to install it first using install.packages("ggthemes") in the console, and then load it using library(ggthemes) in the script.
Error in p1/p2 : non-numeric argument to binary operator
p1 | p2
Error in p1 | p2 : operations are possible only for numeric, logical or complex types
Where goes wrong?
Solution: include library(patchwork) in your script
Easy answer: You forgot to load the patchwork package.
Longer answer:
By default, the symbol, /, is an operator for division and patchwork redefines the symbol to combine the two plots up-and-down.
When the package is not loaded, what R thinks is that p1 and p2 are not numbers that I can do arithmetic, so let me stop and throw an error message.
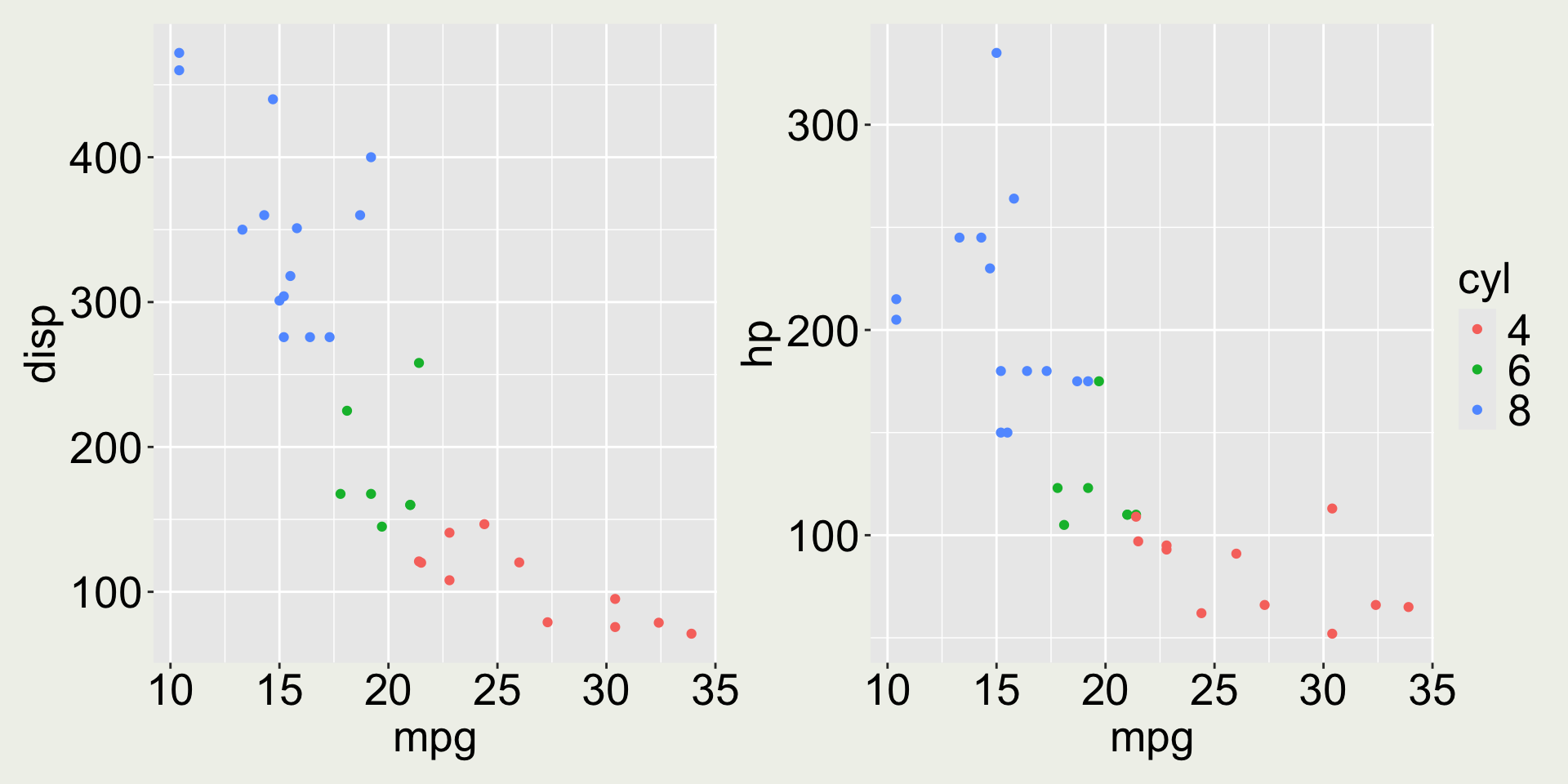
Example: Patchwork
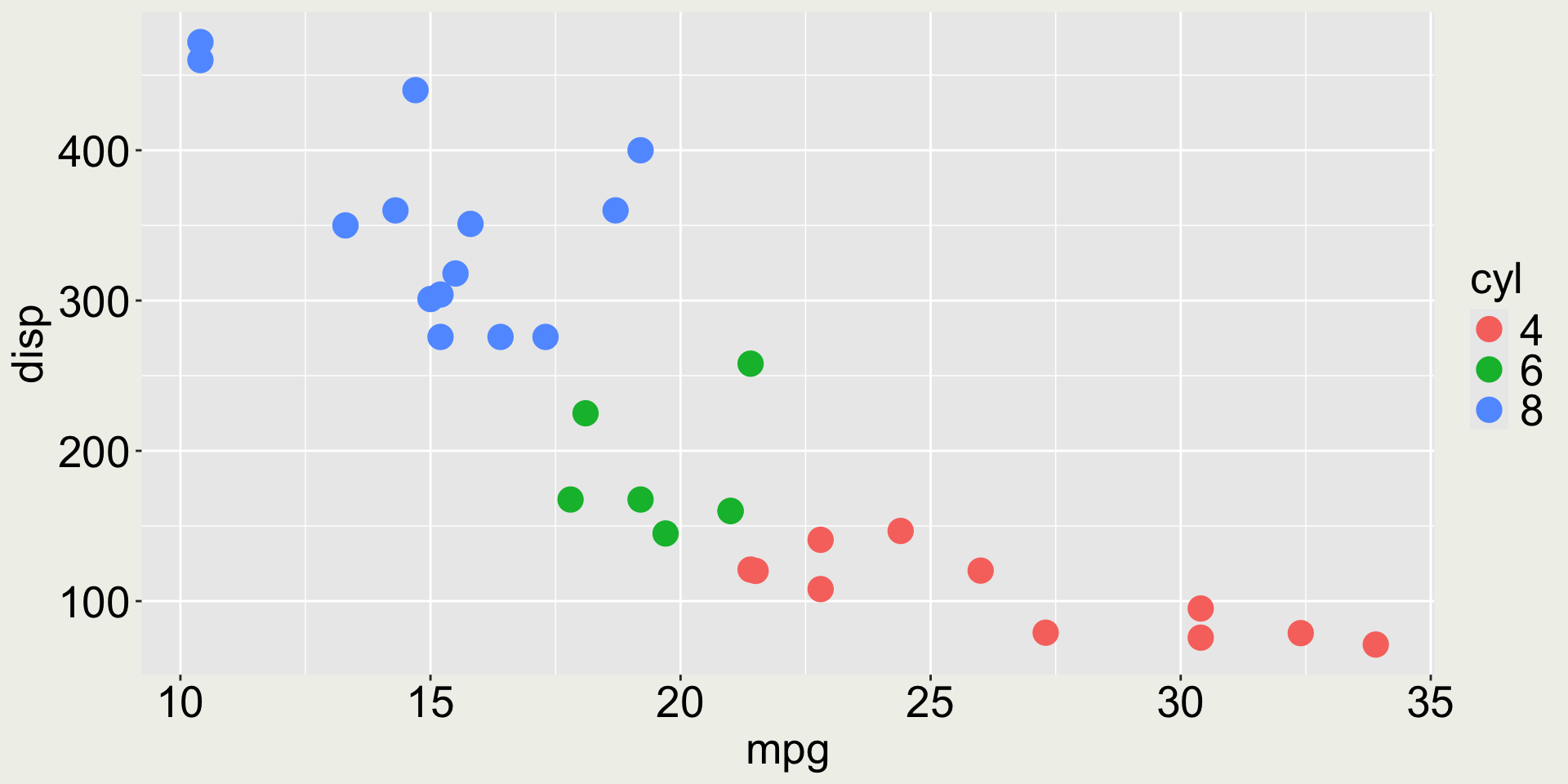
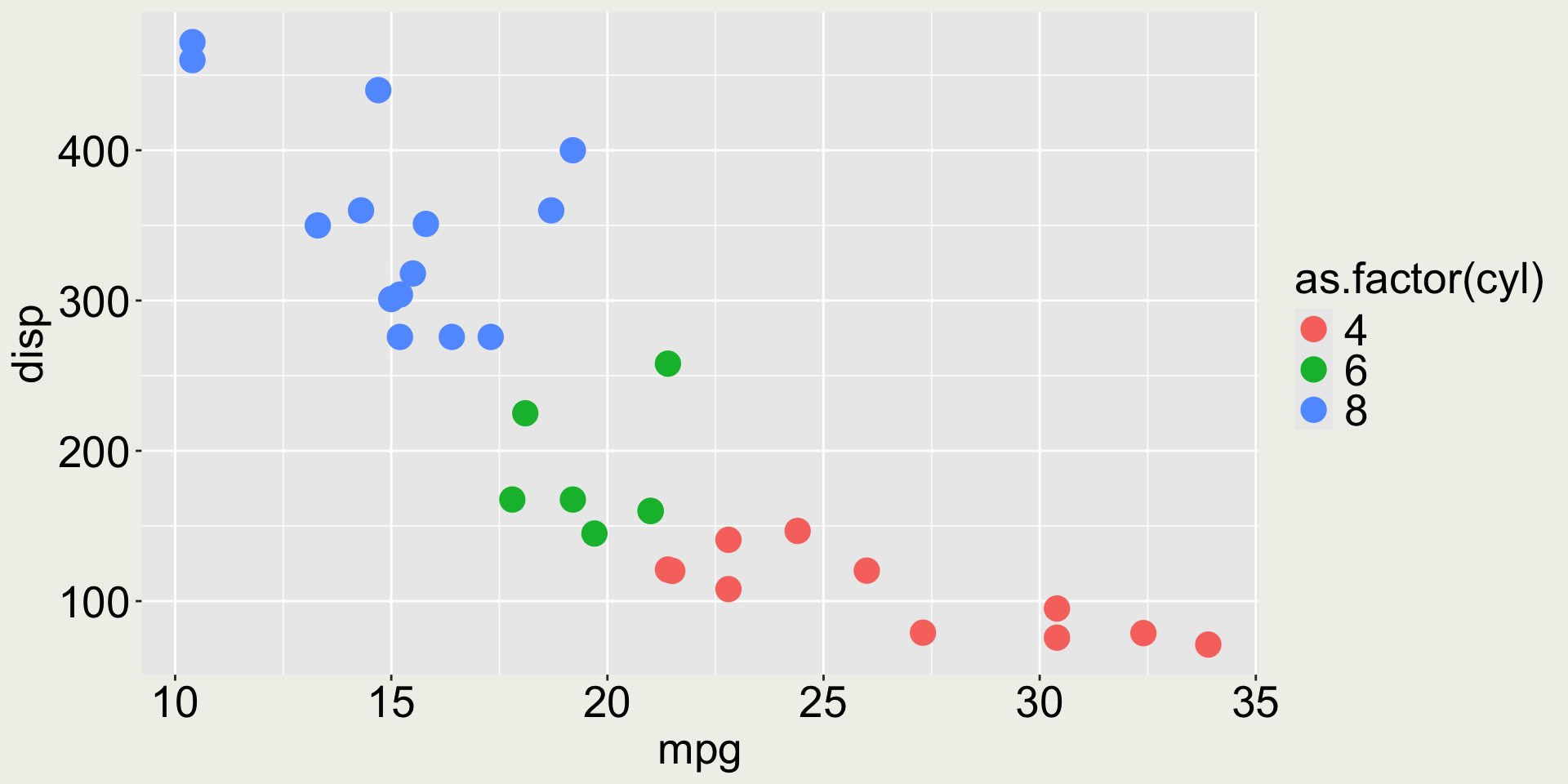
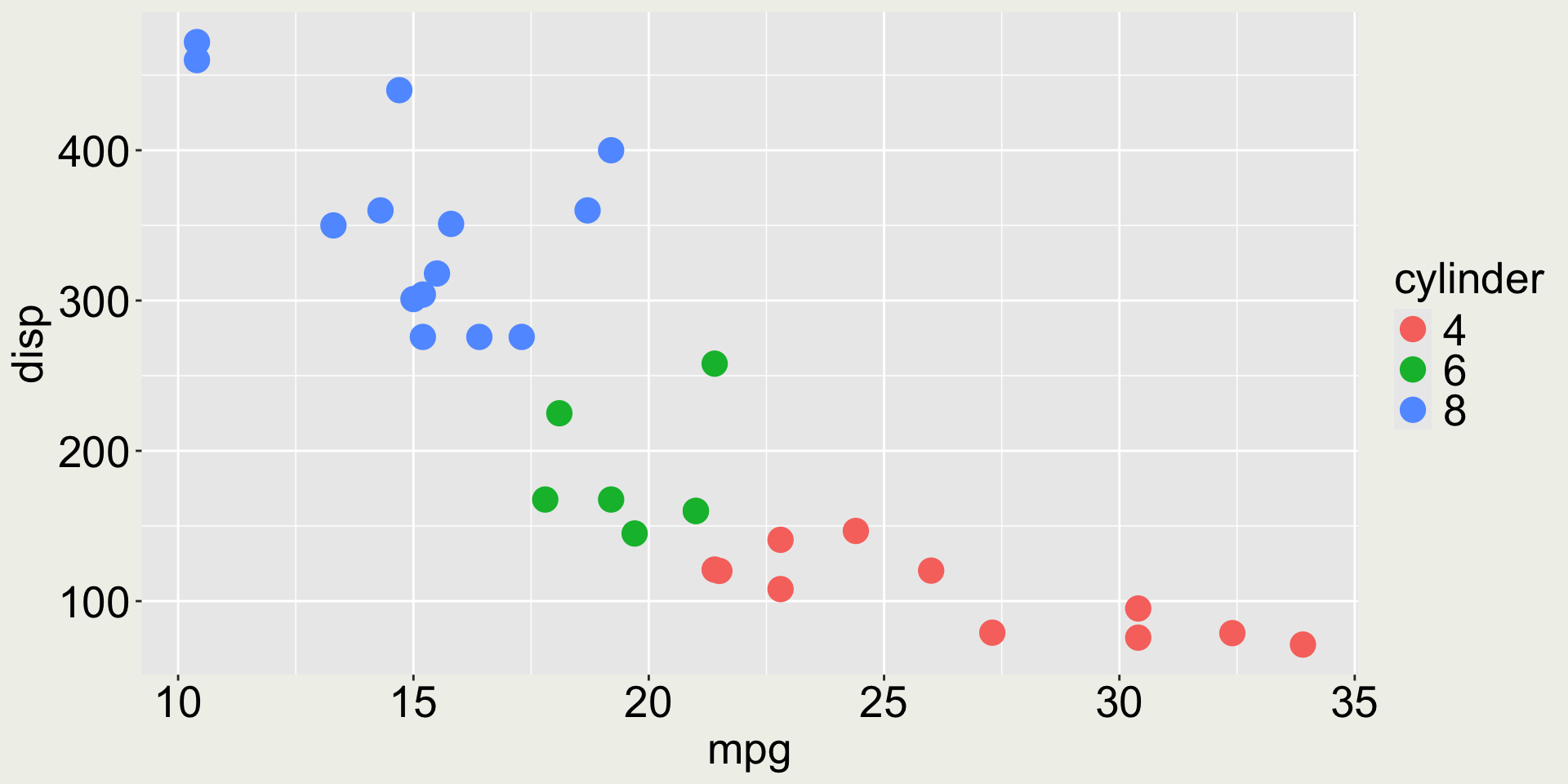
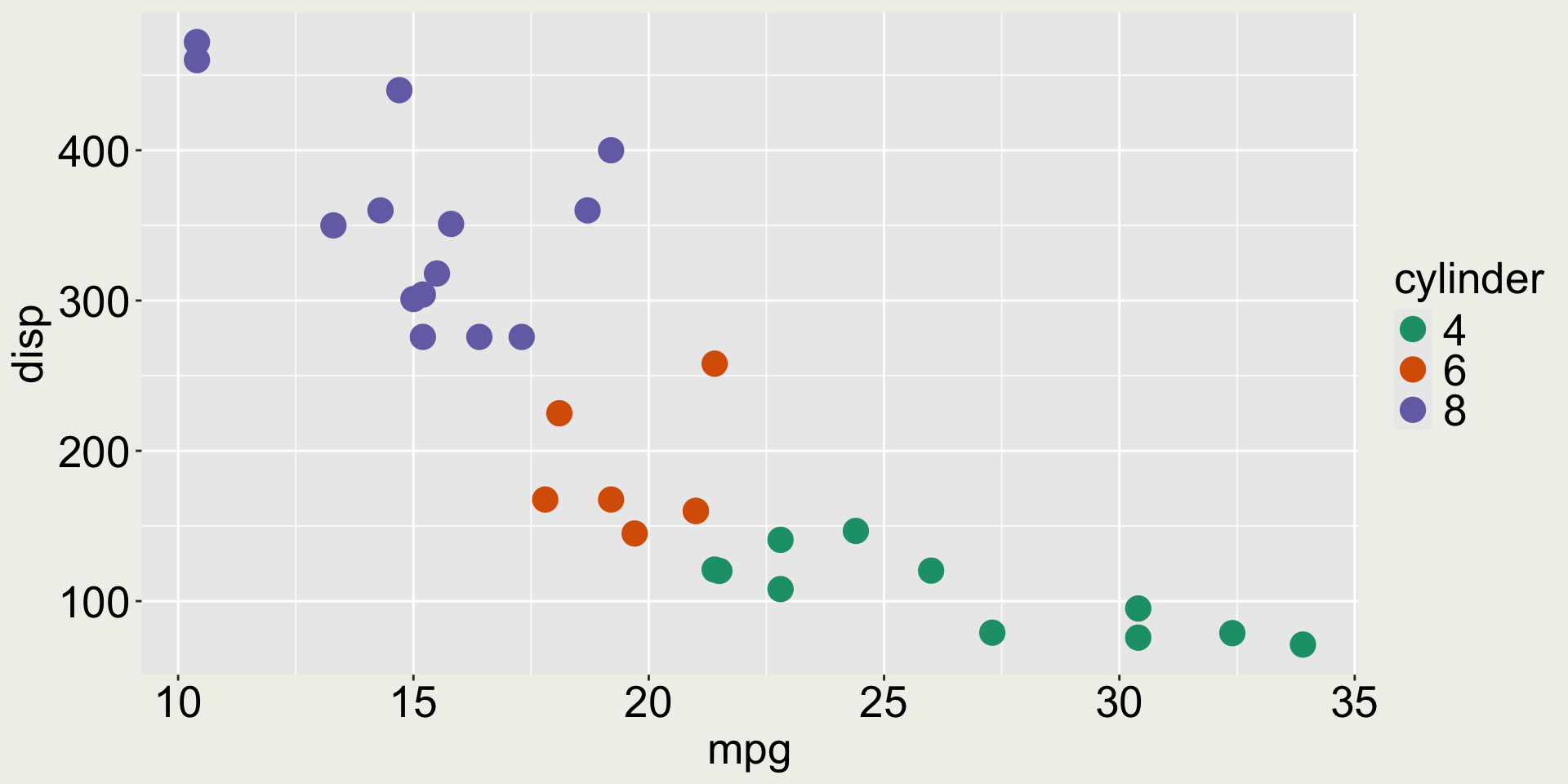
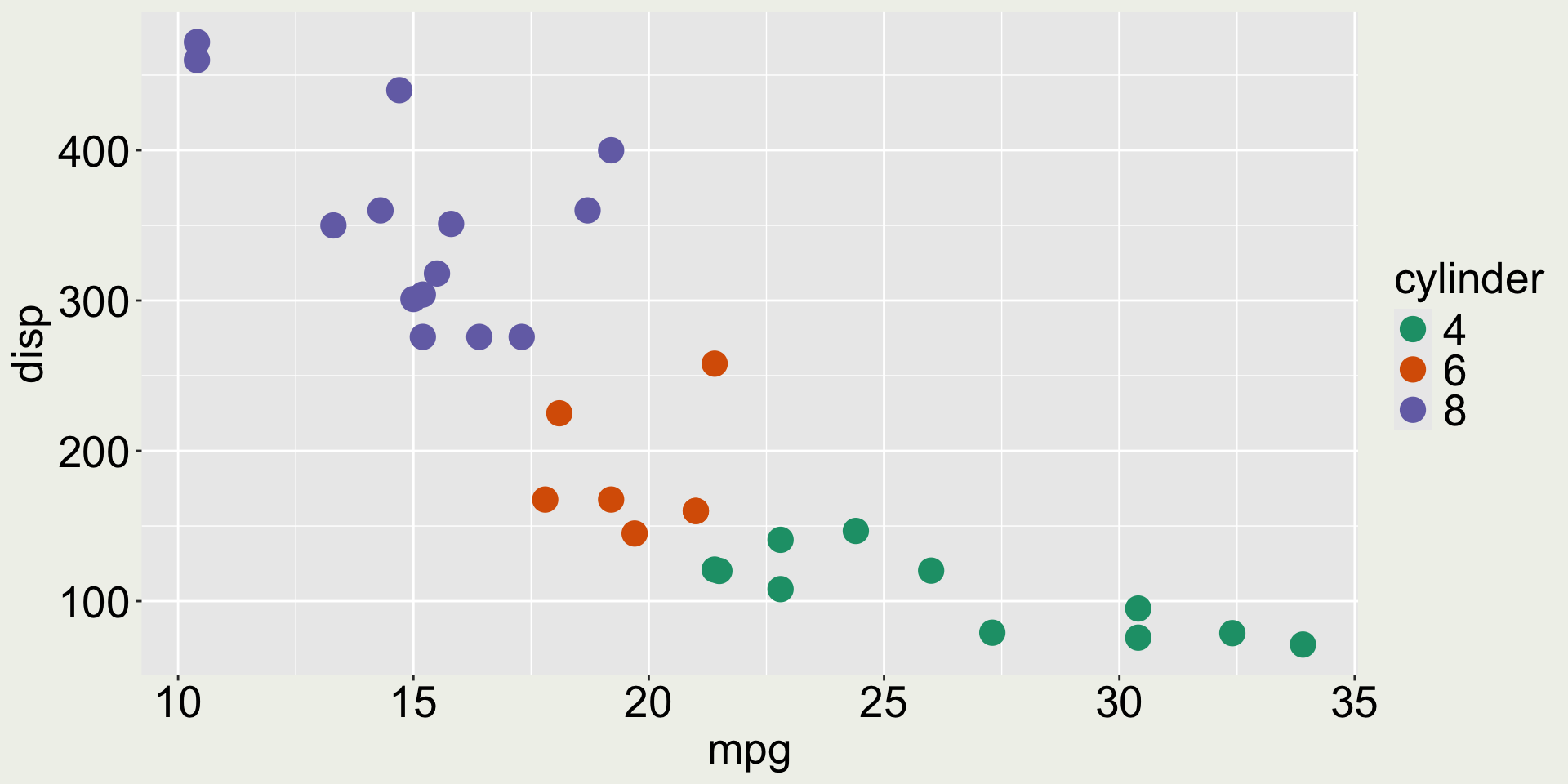
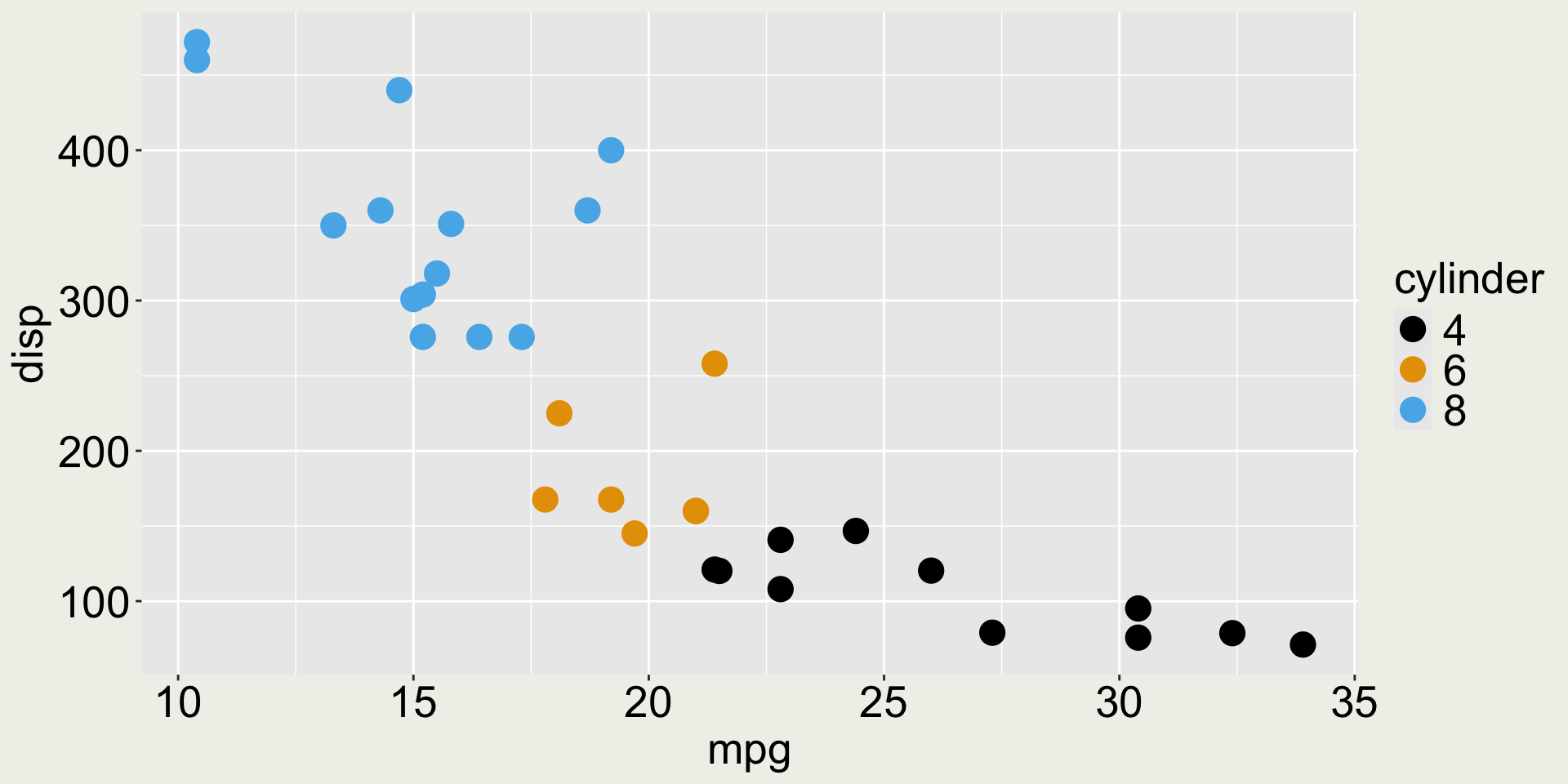
mtcars2 <- mtcars |>mutate(cyl =as.factor(cyl))p1 <-ggplot(mtcars2) +geom_point(aes(x = mpg, y = disp, color = cyl))p2 <-ggplot(mtcars2) +geom_point(aes(x = mpg, y = hp, color = cyl))p1 + p2 # you can also use p1 | p2
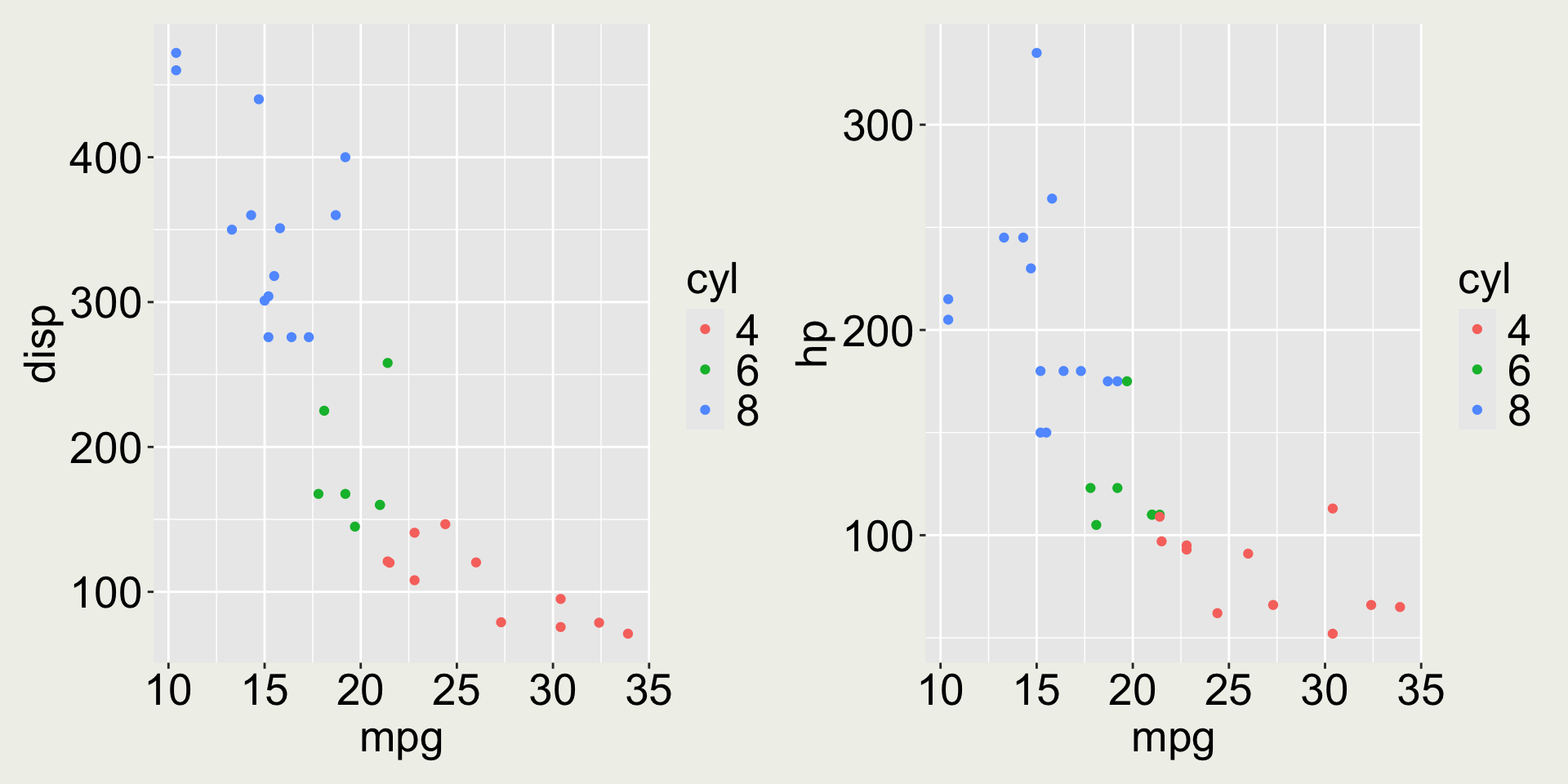
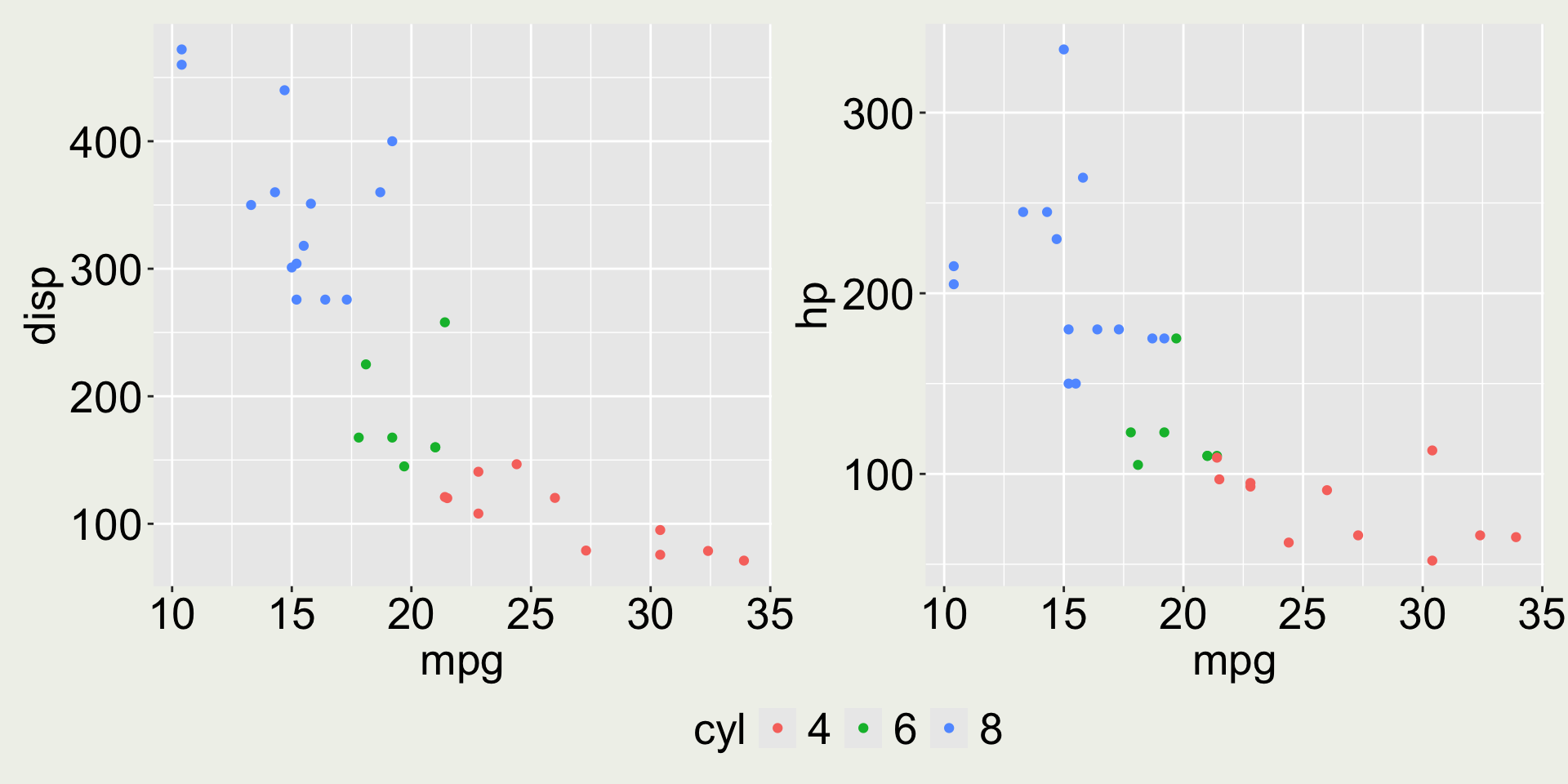
Example: Patchwork
Merge legends together if possible.
p1 + p2 +plot_layout(guides ="collect")
Guide position must be applied to entire patchwork with &
This is likely the only time you will need to use & in this way.
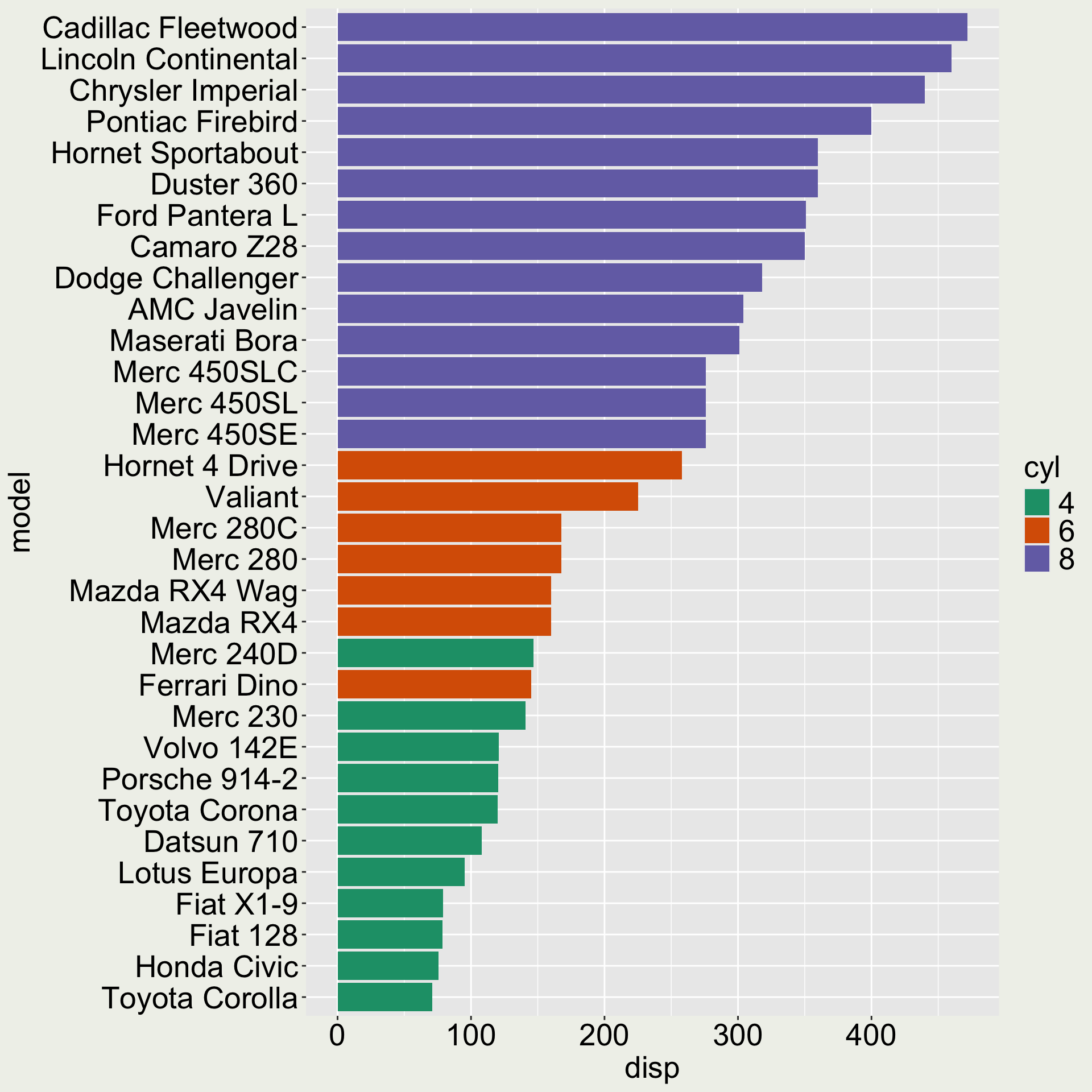
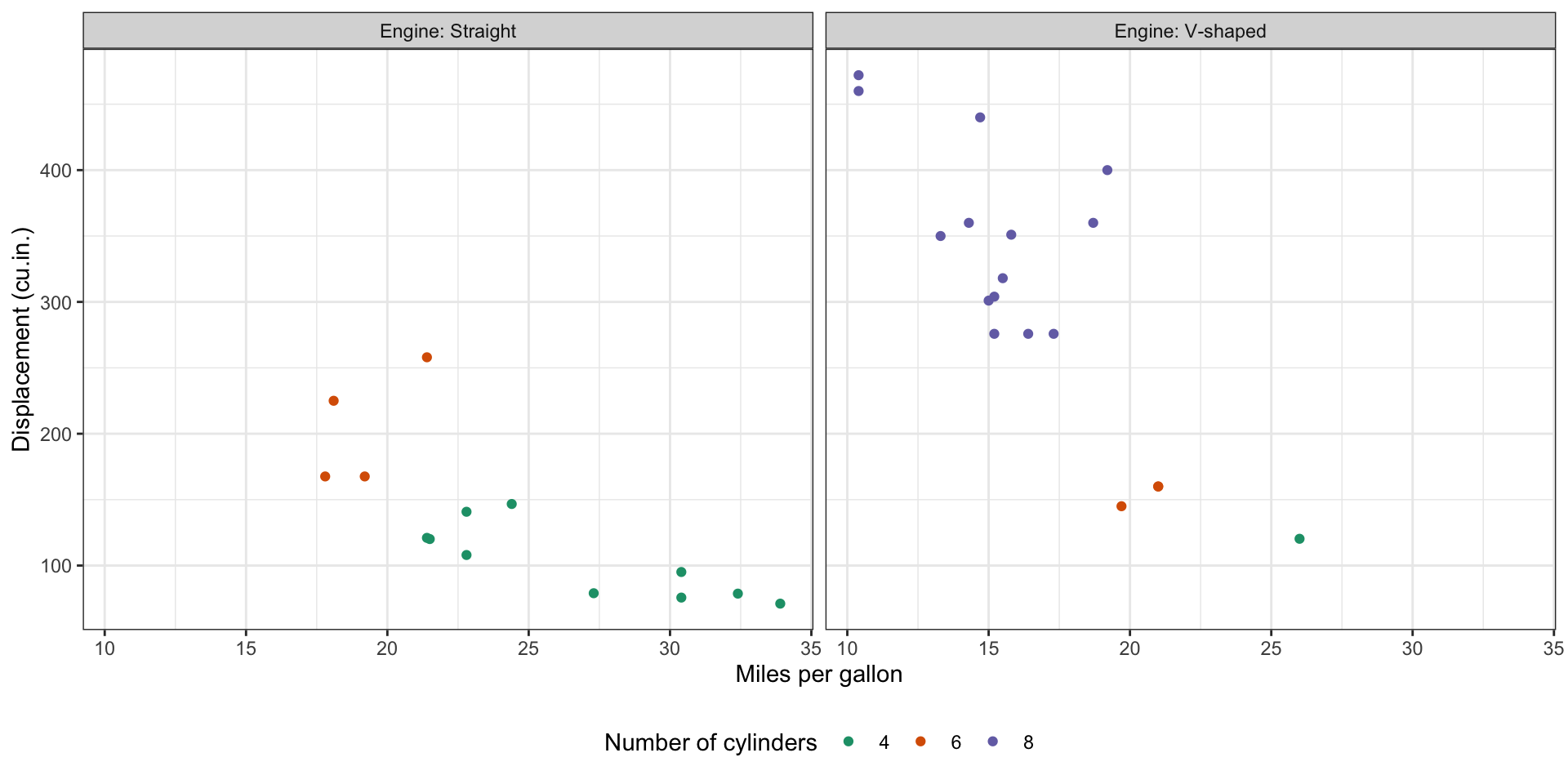
Your time
This is a plot I show you in week1 hello-world.pdf. Can you use the mtcars data with things you’ve learnt from ggplot2 to create the exact same plot?
There are some hints in the next slides to guide you make this plot step-by-step.
Your time
Base plot: Start with a base plot that map the variables in mtcars to the x, y-axis, color, and facet.
Color: The color seems to be mapped to a continuous value. Is it the best choice? How would you change it? What’s the scale_xxx_xxx() function to change to a different color palette.
Facet: The facet header (0 and 1) are not informative, how would you change it. Maybe we can recode 0 and 1 to its actual meaning. How would you do that?
Labels: Use a more informative x and y axis title, and legend name
Theme: Play around with theme and arrange the legend position to bottom